
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- pyenv
- 가상환경
- 4948
- n과 m
- 1002
- Mac
- 신경망 학습
- 15649
- 밑바닥부터 시작하는 딥러닝
- N-Queen
- 설정
- 재귀
- 개발환경
- 손실함수
- BOJ
- 경사하강법
- 그리디 알고리즘
- 백트래킹
- 파이싼
- 파이썬
- 실버
- Python
- streamlit
- 기계학습
- end to end
- 1101
- 백준
- 9020
- Today
- Total
파이톨치
[Paper review] Co-DETR 본문
DETRs with Collaborative Hybrid Assignments Training
Abstract
이 논문에서는 DETR(객체 탐지 모델)에서 일대일 매칭으로 인해 소수의 쿼리가 양성 샘플로 할당되는 경우, 인코더 출력에 대한 희소한 감독이 발생하여 인코더의 판별적 특징 학습이 크게 저하된다는 관찰을 제시합니다. 이는 디코더의 어텐션 학습에도 부정적인 영향을 미칩니다.
여기서 "일대일 매칭"은 객체 탐지 모델에서 입력 이미지의 객체와 예측된 쿼리 간의 매칭 방식을 의미합니다. 여기서 소수의 쿼리가 양성 샘플로 할당된다는 것은, 전체 쿼리(모델이 예측하는 객체의 수) 중 일부만 실제로 이미지에서 존재하는 객체와 올바르게 매칭된다는 것을 나타냅니다.
- 쿼리(Query): DETR과 같은 모델에서, 쿼리는 탐지하려는 객체를 나타내는 예측값입니다. 보통 이미지에서 감지된 객체의 위치와 클래스 정보를 포함합니다.
- 양성 샘플(Positive Sample): 모델이 실제로 존재하는 객체와 올바르게 매칭된 쿼리를 의미합니다. 즉, 이 쿼리는 실제 객체를 잘 표현하고 있습니다.
- 일대일 매칭: 각 객체에 대해 하나의 쿼리만을 할당하는 방식입니다. 이 경우, 이미지의 객체가 적거나 특정 객체에 대한 쿼리만이 잘 매칭될 수 있습니다.
- 희소한 감독(Sparse Supervision): 양성 샘플이 소수로 제한되면, 모델은 적은 양의 정보만을 학습하게 됩니다. 즉, 인코더는 다양한 객체의 특징을 잘 학습하지 못하고, 결과적으로 모델의 성능이 저하될 수 있습니다.
이를 해결하기 위해, 우리는 다양한 라벨 할당 방식을 통해 더 효율적이고 효과적인 DETR 기반 탐지기를 학습할 수 있는 새로운 협력적 하이브리드 할당 훈련 방식(Co-DETR)을 제안합니다. 이 새로운 훈련 방식은 ATSS 및 Faster RCNN과 같은 일대다 라벨 할당 방식을 사용하여 여러 병렬 보조 헤드를 훈련시킴으로써 인코더의 학습 능력을 쉽게 향상시킬 수 있습니다.
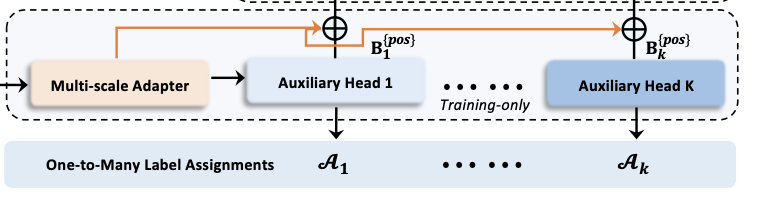
또한, 이러한 보조 헤드에서 양성 좌표를 추출하여 디코더에서 양성 샘플의 학습 효율성을 높이는 맞춤형 양성 쿼리도 추가로 설계합니다.

추론 시, 이 보조 헤드는 삭제되므로 추가적인 매개변수나 계산 비용이 발생하지 않으며, 수동으로 설계된 비최대 억제(NMS)가 필요하지 않습니다.

우리는 DAB-DETR, Deformable-DETR, DINO-Deformable-DETR와 같은 DETR 변형 모델에서 제안된 접근 방식의 효과를 평가하기 위해 광범위한 실험을 수행했습니다. Swin-L을 사용한 최첨단 DINO-Deformable-DETR의 경우 COCO val 데이터셋에서 58.5% AP에서 59.5% AP로 성능이 향상되었습니다. 놀랍게도, ViT-L 백본과 결합하면 COCO test-dev에서 66.0% AP, LVIS val에서 67.9% AP를 달성하여, 이전 방법보다 훨씬 적은 모델 크기로도 명확한 차이로 성능을 능가했습니다.
Introduction
물체 탐지는 물체를 위치 지정하고 그 범주를 분류해야 하는 컴퓨터 비전의 기본 작업입니다. R-CNN 계열의 선구적인 연구와 ATSS, RetinaNet, FCOS, PAA와 같은 다양한 변형들은 물체 탐지 작업에서 중요한 돌파구를 마련했습니다. 이들 방법의 핵심 방식은 일대다(label assignment) 라벨 할당으로, 각 실제 박스가 탐지기 출력의 여러 좌표에 할당되어 제안들과 함께 감독된 타겟으로 작용합니다.
이러한 모델들은 유망한 성능에도 불구하고 비최대 억제(NMS) 절차나 앵커 생성과 같은 많은 수작업으로 설계된 요소에 의존합니다. 보다 유연한 엔드 투 엔드 탐지기를 구현하기 위해, DEtection TRansformer (DETR)가 제안되어 물체 탐지를 집합 예측 문제로 간주하고 트랜스포머 인코더-디코더 아키텍처 기반의 일대일 집합 매칭 방식을 도입했습니다. 이러한 방식에서는 각 실제 박스가 특정 쿼리에만 할당되고, 사전 지식을 인코딩하는 여러 수작업 설계 요소가 더 이상 필요하지 않습니다. 이 접근 방식은 유연한 탐지 파이프라인을 도입하고 많은 DETR 변형들이 이를 통해 더 개선될 수 있도록 합니다. 그러나 기본적인 엔드 투 엔드 물체 탐지기의 성능은 여전히 일대다 라벨 할당 방식을 사용하는 전통적인 탐지기보다 낮습니다.
이 논문에서는 DETR 기반 탐지기가 전통적인 탐지기보다 우수하도록 하면서 그들의 엔드 투 엔드 장점을 유지하는 방법을 제시하고자 합니다. 이러한 도전 과제를 해결하기 위해, 우리는 일대일 집합 매칭 방식의 직관적인 단점인 긍정적 쿼리가 적게 탐색된다는 점에 주목했습니다. 이는 심각한 비효율적인 학습 문제로 이어집니다. 우리는 인코더가 생성하는 잠재 표현과 디코더의 어텐션 학습이라는 두 가지 측면에서 이를 자세히 분석했습니다.
먼저, 우리는 Deformable-DETR와 일대다 라벨 할당 방법 간의 잠재 특징의 판별 가능성 점수를 비교했습니다. 이때 단순히 ATSS 헤드로 디코더를 교체했습니다. 각 공간 좌표에서 특징의 l₂-노름을 사용하여 판별 가능성 점수를 표현합니다. 인코더의 출력 F ∈ R^C×H×W가 주어지면, 우리는 판별 가능성 점수 맵 S ∈ R^1×H×W를 얻을 수 있습니다. 해당 영역의 점수가 높을수록 물체를 더 잘 탐지할 수 있습니다.
그림 2에 표시된 바와 같이, 우리는 판별 가능성 점수에 대해 다양한 임계값을 적용하여 IoF-IoB 곡선을 보여줍니다(IoF: 전경 교차, IoB: 배경 교차). ATSS에서의 더 높은 IoF-IoB 곡선은 전경과 배경을 구별하기가 더 쉽다는 것을 나타냅니다. 우리는 또한 그림 3에서 판별 가능성 점수 맵 S를 시각화했습니다. 일부 두드러진 영역에서 특징이 완전히 활성화된 것은 일대다 라벨 할당 방식인 반면, 일대일 집합 매칭에서는 덜 탐색된 것이 분명합니다. 디코더 훈련의 탐색을 위해, 우리는 또한 Deformable-DETR와 긍정적 쿼리를 더 많이 도입하는 Group-DETR의 교차 어텐션 점수의 IoF-IoB 곡선을 보여줍니다. 그림 2에 나타난 바와 같이, 긍정적 쿼리가 너무 적으면 어텐션 학습에도 영향을 미치며, 디코더에서 긍정적 쿼리를 늘리면 이 문제를 약간 완화할 수 있습니다.

이러한 중요한 관찰은 우리에게 간단하지만 효과적인 방법인 협력적 하이브리드 할당 훈련 방식(Co-DETR)을 제시하도록 동기를 부여합니다. Co-DETR의 핵심 통찰력은 다양한 일대다 라벨 할당을 사용하여 인코더와 디코더의 학습 효율성을 향상시키는 것입니다. 보다 구체적으로, 우리는 보조 헤드를 트랜스포머 인코더의 출력과 통합합니다. 이러한 헤드는 ATSS, FCOS 및 Faster RCNN과 같은 다양한 일대다 라벨 할당으로 감독될 수 있습니다. 다양한 라벨 할당은 인코더의 출력에 대한 감독을 풍부하게 하여 학습 수렴을 지원하는 데 필요한 충분한 판별성을 강요합니다. 디코더의 학습 효율성을 더욱 개선하기 위해, 우리는 이러한 보조 헤드에서 긍정적 샘플의 좌표를 정교하게 인코딩합니다. 긍정적 앵커 및 긍정적 제안이 포함되어 있으며, 이들은 원래 디코더에 여러 그룹의 긍정적 쿼리로 전달되어 미리 할당된 카테고리와 경계 상자를 예측합니다. 각 보조 헤드의 긍정적 좌표는 다른 그룹과 분리된 독립적인 그룹으로 작용합니다. 다양한 일대다 라벨 할당은 디코더의 학습 효율성을 향상시키기 위해 풍부한 (긍정적 쿼리, 실제 값) 쌍을 도입할 수 있습니다. 참고로, 추론 중에는 원래 디코더만 사용되므로 제안된 훈련 방식은 훈련 중에만 추가 오버헤드를 도입합니다.
우리는 제안된 방법의 효율성과 효과를 평가하기 위해 광범위한 실험을 수행했습니다. 그림 3에 나타난 바와 같이, Co-DETR은 일대일 집합 매칭에서 인코더의 특징 학습 문제를 크게 완화합니다. 플러그 앤 플레이 방식으로 우리는 DAB-DETR, Deformable-DETR 및 DINO-Deformable-DETR과 같은 다양한 DETR 변형과 쉽게 결합할 수 있습니다.

그림 1에 나타난 바와 같이, Co-DETR은 더 빠른 훈련 수렴과 더 높은 성능을 달성합니다. 구체적으로, 우리는 기본 Deformable-DETR을 12 에포크 훈련 시 5.8% AP 향상시켰고, 36 에포크 훈련 시 3.2% AP 향상시켰습니다. DINO-Deformable-DETR은 Swin-L을 사용하여 COCO val에서 58.5%에서 59.5% AP로 성능이 향상될 수 있습니다. 놀랍게도, ViT-L 백본과 결합하여 COCO test-dev에서 66.0% AP, LVIS val에서 67.9% AP를 달성하여 훨씬 적은 모델 크기로 새로운 최첨단 탐지기를 수립했습니다.
Related Works
one to many (label assignment)
물체 탐지에서 일대다 라벨 할당을 위해, 여러 박스 후보가 훈련 단계에서 같은 실제 박스에 긍정적 샘플로 할당될 수 있습니다. Faster-RCNN [27] 및 RetinaNet [21]과 같은 전통적인 앵커 기반 탐지기에서는 샘플 선택이 미리 정의된 IoU 임계값과 앵커와 주석 박스 간의 일치하는 IoU에 의해 안내됩니다. 앵커가 없는 FCOS는 중심 우선순위를 활용하여 각 경계 상자의 중심 근처의 공간 위치를 긍정적 샘플로 할당합니다. 게다가, ATSS는 고정된 라벨 할당의 한계를 극복하기 위해 적응 메커니즘을 일대다 라벨 할당에 통합합니다. ATSS는 상위 k개의 가장 가까운 앵커의 통계적 동적 IoU 값을 통해 적응형 앵커 선택을 수행합니다. PAA는 확률적인 방식으로 앵커를 긍정적 및 부정적 샘플로 적응적으로 분리합니다. 본 논문에서는 보조 헤드를 통해 일대다 라벨 할당을 이용하여 인코더 표현을 개선하기 위한 협력적 하이브리드 할당 방식을 제안합니다.
one to one 집합 매칭
선구적인 트랜스포머 기반 탐지기인 DETR [1]는 물체 탐지에 일대일 집합 매칭 방식을 통합하고 완전한 엔드 투 엔드 물체 탐지를 수행합니다.
일대일 집합 매칭 전략은 먼저 헝가리안 매칭을 통해 전역 매칭 비용을 계산하고, 각 실제 박스에 대해 최소 매칭 비용을 가진 하나의 긍정적 샘플만 할당합니다. DNDETR [18]는 일대일 집합 매칭의 불안정성에서 발생하는 느린 수렴 결과를 보여주며, 이 문제를 해결하기 위해 노이즈 제거 훈련을 도입합니다. DINO [39]는 DAB-DETR [23]의 고급 쿼리 형식을 계승하고, 상태-of-더-아트 성능을 달성하기 위해 개선된 대조 노이즈 제거 기술을 통합합니다. Group-DETR [5]는 그룹별 일대다 라벨 할당을 구성하여 여러 긍정적 물체 쿼리를 활용하는데, 이는 H-DETR [16]의 하이브리드 매칭 방식과 유사합니다. 위의 후속 연구와는 대조적으로, 우리는 일대일 집합 매칭에 대한 협력적 최적화의 새로운 관점을 제시합니다.
Method
Overview
표준 DETR 프로토콜에 따라, 입력 이미지는 백본과 인코더에 공급되어 잠재적 특성을 생성합니다. 이후 여러 개의 미리 정의된 물체 쿼리가 디코더에서 크로스 어텐션을 통해 이들과 상호작용합니다. 우리는 협력적 하이브리드 할당 훈련 방식과 맞춤형 긍정적 쿼리 생성을 통해 인코더에서의 특성 학습과 디코더에서의 어텐션 학습을 개선하기 위해 Co-DETR을 도입합니다. 이러한 모듈을 자세히 설명하고, 이들이 잘 작동할 수 있는 이유에 대한 통찰을 제공하겠습니다.
Collaborative Hybrid Assignments Training
디코더에서 긍정적인 쿼리가 적어 인코더의 출력에 대한 감독이 부족한 문제를 완화하기 위해, 우리는 다양한 일대다 레이블 할당 방식(예: ATSS, Faster R-CNN)을 사용하는 보조 헤드를 통합합니다. 서로 다른 레이블 할당 방식을 통해 인코더의 출력에 대한 감독이 풍부해져, 이 보조 헤드들의 학습 수렴을 지원할 수 있을 만큼 충분히 판별력 있는 특징을 형성하게 합니다. 구체적으로, 인코더의 잠재적 특성 F가 주어지면, 우리는 다중 스케일 어댑터를 통해 이를 피라미드 형태의 특성 {F1, · · · , FJ}로 변환합니다. 여기서 J는 2^2+J 다운샘플링 스트라이드를 가진 특성 맵을 의미합니다. ViTDet [20]와 유사하게, 피라미드 특성은 단일 스케일 인코더에서 단일 특성 맵으로 구성되며, 우리는 업샘플링을 위해 쌍선형 보간법과 3×3 컨볼루션을 사용합니다. 예를 들어, 인코더의 단일 스케일 특성을 사용하여 다운샘플링(스트라이드 2의 3×3 컨볼루션) 또는 업샘플링 연산을 순차적으로 적용하여 피라미드 특성을 생성합니다. 다중 스케일 인코더의 경우, 우리는 다중 스케일 인코더 특성 F에서 가장 거친 특성만 다운샘플링하여 피라미드 특성을 구축합니다.
각각의 레이블 할당 방식 Ak에 대응하는 K개의 협력 헤드가 정의되며, i번째 협력 헤드에서 {F1, · · · , FJ}는 예측 값 Pˆi를 얻기 위해 해당 헤드로 전달됩니다. i번째 헤드에서 Ai는 Pˆi의 긍정 샘플과 부정 샘플에 대한 감독 목표를 계산합니다. G를 실제 값 집합으로 나타내면, 이 과정은 다음과 같이 수식화할 수 있습니다:
저기서 말하는 "레이블 할당 방식(A)"는 객체 검출 모델에서 객체 후보군(anchors 또는 queries)과 실제 값(ground-truth) 간의 매칭 방식을 의미합니다. 이 매칭 과정에서, 어떤 후보가 양성(positive) 샘플로 간주될지, 또는 음성(negative) 샘플로 간주될지 결정됩니다.
레이블 할당 방식은 주로 두 가지 형태로 나뉩니다:
- 일대다 레이블 할당 (One-to-Many Assignment):
- 여러 객체 후보군이 하나의 실제 값에 대응됩니다. 즉, 여러 후보가 동일한 실제 객체를 양성 샘플로 학습하게 됩니다.
- 예: ATSS(Adaptive Training Sample Selection), Faster R-CNN 같은 방식은 여러 후보가 일정한 조건(IoU 임계값, 거리 등)을 만족하면 그 후보들을 모두 양성 샘플로 할당합니다.
- 일대일 레이블 할당 (One-to-One Assignment):
- 하나의 객체 후보군만 하나의 실제 값과 대응됩니다. 즉, 각 실제 객체는 단 하나의 후보에만 매칭됩니다.
- 예: DETR(Denoising Transformer)은 헝가리안 매칭 알고리즘을 사용하여, 각 실제 객체와 가장 잘 맞는 하나의 후보를 찾아 양성 샘플로 할당합니다.
A는 이런 레이블 할당 방식을 나타내는 매커니즘이며, 각 레이블 할당 방식은 모델이 어떤 기준으로 양성/음성 샘플을 선택할지 결정합니다. 여기서 각 "협력 헤드"가 서로 다른 레이블 할당 방식을 따르게 되면, 다양한 방식으로 인코더 출력에 대한 감독이 가능해져 더 강력한 특징 표현을 학습할 수 있게 됩니다.
이 논문에서는 각 헤드가 일대다(One-to-Many) 레이블 할당 방식을 사용합니다.
논문에서 언급된 내용에 따르면, 다양한 보조 헤드(auxiliary heads)가 각각 다른 일대다 레이블 할당 방식을 따르고 있으며, 이를 통해 인코더 출력에 대한 다양한 감독 신호를 제공합니다. 예를 들어, ATSS나 Faster R-CNN 같은 일대다 방식의 레이블 할당이 언급되고 있습니다. 이런 방식은 여러 객체 후보를 동일한 실제 객체와 양성 샘플로 매칭하는 특징이 있습니다.

여기서 {pos}와 {neg}는 구인구Ai에 의해 결정된 (j, FJ 내 긍정 또는 부정 좌표)의 쌍 집합을 나타냅니다. j는 {F1, · · · , FJ}에서 특성 인덱스를 의미합니다. B {pos} i는 공간적 긍정 좌표들의 집합을 나타내며, P {pos} i와 P {neg} i는 해당 좌표에서의 감독 목표로, 카테고리와 회귀 오프셋을 포함합니다. 각 변수에 대한 자세한 정보는 표 1에 설명되어 있습니다. 손실 함수는 다음과 같이 정의될 수 있습니다:


여기서 부정 샘플에 대한 회귀 손실은 제외됩니다. K개의 보조 헤드에 대한 최적화의 훈련 목표는 다음과 같이 수식화됩니다:

Why Co-DETR works
Co-DETR는 DETR 기반 탐지기에서 명확한 성능 향상을 가져옵니다. 다음으로, 우리는 이 방법의 효과를 질적 및 양적으로 분석하려고 합니다. ResNet50 백본을 사용하는 Deformable-DETR 기반의 36-epoch 설정을 바탕으로 상세한 분석을 진행했습니다.
인코더의 감독 강화: 직관적으로, 양성 쿼리가 너무 적으면 각 실제 객체에 대해 하나의 쿼리만이 회귀 손실에 의해 감독을 받기 때문에 드문드문한 감독이 발생합니다. 일대다 레이블 할당 방식에서 양성 샘플은 더 많은 위치 감독을 받아 잠재적 특징 학습을 강화하는 데 도움이 됩니다. 드문드문한 감독이 모델 학습에 어떻게 방해가 되는지 더 탐구하기 위해, 우리는 인코더가 생성하는 잠재적 특징을 상세히 조사했습니다. 우리는 인코더 출력의 판별 가능성을 정량화하기 위해 IoF-IoB 곡선을 도입했습니다. 구체적으로, 인코더의 잠재적 특징 F가 주어졌을 때, Figure 3에서 보여지는 특징 시각화를 참고하여 IoF(Intersection over Foreground)와 IoB(Intersection over Background)를 계산합니다.
우리는 ATSS, Deformable-DETR, 그리고 Co-Deformable-DETR의 판별 점수를 Figure 3에서 시각화했습니다. Deformable-DETR와 비교했을 때, ATSS와 Co-Deformable-DETR은 주요 객체 영역을 더 잘 구분하는 능력을 갖추고 있으며, Deformable-DETR은 배경에 방해받고 있는 것을 확인할 수 있습니다.
헝가리안 매칭 불안정성 감소를 통한 크로스 어텐션 학습 개선: 헝가리안 매칭은 일대일 세트 매칭의 핵심 방식입니다. 크로스 어텐션는 양성 쿼리가 풍부한 객체 정보를 인코딩하는 데 중요한 역할을 합니다. 이 과정은 충분한 학습이 필요합니다. 그러나 우리는 헝가리안 매칭이 훈련 과정에서 동일 이미지 내에서 양성 쿼리에 할당된 실제 객체가 계속 바뀌면서 제어할 수 없는 불안정성을 도입한다는 것을 관찰했습니다. 우리는 Figure 5에서 불안정성 비교를 제시했으며, 우리의 접근법이 더 안정적인 매칭 과정을 기여한다는 것을 발견했습니다.
논문에서 언급된 내용에 따르면, 헝가리안 매칭 과정이 쿼리와 실제 객체를 매칭하는 데 사용되며, 이 과정에서 매칭된 쿼리가 정확하게 이미지 피처 맵의 객체 정보를 참조하도록 하기 위해 크로스 어텐션이 사용됩니다. 하지만 이 과정이 불안정할 수 있는데, 그 이유는 매칭된 쿼리-객체 쌍이 학습 과정에서 계속 변할 수 있기 때문입니다. 이러한 불안정성은 모델 학습을 방해할 수 있으며, 이를 개선하기 위한 방법으로 더 많은 양의 긍정적 쿼리를 생성하여 모델이 더 효율적으로 학습할 수 있도록 돕는 방식이 제안됩니다.

Conclusions
이 논문에서는 Co-DETR라는 새로운 협업형 하이브리드 할당 방식 학습 기법을 제시합니다. 이를 통해 다양한 레이블 할당 방식을 사용하여 DETR(Detection Transformer) 기반 탐지기의 효율성과 성능을 높일 수 있습니다. 이 새로운 학습 기법은 다중 병렬 보조 헤드를 통해 일대다 레이블 할당을 학습시키며, 이를 통해 엔드 투 엔드(End-to-End) 탐지기의 인코더 학습 능력을 쉽게 향상시킬 수 있습니다. 또한, 보조 헤드에서 추출한 긍정적 좌표를 사용하여 디코더에서 긍정적 샘플의 학습 효율성을 높이는 맞춤형 긍정 쿼리를 추가로 생성합니다. COCO 데이터셋에서 수행한 광범위한 실험을 통해 Co-DETR의 효율성과 효과가 입증되었습니다. 특히, ViT-L 백본과 결합했을 때 COCO 테스트 개발(Test-dev) 세트에서 66.0% AP, LVIS 검증(Val) 세트에서 67.9% AP를 달성하여, 더 적은 모델 크기로 새로운 최첨단 탐지기를 구현했습니다.
'AI&ML' 카테고리의 다른 글
| [개념정리] NMS, NMW (0) | 2024.10.22 |
|---|---|
| [Robot] ros&gazebo 이륜차 만들기 (1) | 2024.08.26 |
| [부스트캠프] 프리코스 정리 (1) | 2024.07.05 |
| [부스트캠프] 인공지능 기초 다지기 - 딥러닝 - Layer (1) | 2024.07.03 |
| [부스트캠프] 인공지능 기초 다지기 - 딥러닝 - PyTorch (1) | 2024.07.03 |

