
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 티스토리챌린지
- Retrieval
- Python
- N-Queen
- 15649
- REST API
- 파이썬
- streamlit
- 가상환경
- 개발환경
- 파이싼
- BOJ
- 오블완
- 백트래킹
- 백준
- 1002
- 재귀
- pyenv
- 1101
- 신경망 학습
- video retireval
- n과 m
- end to end
- 4948
- 그리디 알고리즘
- 경사하강법
- 기계학습
- 9020
- 밑바닥부터 시작하는 딥러닝
- 손실함수
- Today
- Total
파이톨치
[BoostCamp AI Tech] CV 이론 복습 문제 본문
[문제 출처: BoostCamp AI Tech 7기 유지환님]
1. FCN의 단점을 설명하고 CNN의 장점을 설명해주세요
FCN은 Fully Connected Network의 준말이다. 이 구조를 사용하게 되는 경우에 "모든 입력 뉴련과 출력 뉴런이 연결되기 때문에" 계산량이 많이진다. n 길이의 벡터가 있을 때, h 길이의 hidden vector로 연산을 하게 되는 경우에, n x h 크기의 행렬이 필요하기 때문이다. 이미지와 같이 사이즈가 큰 입력 데이터가 들어오면 그 계산량은 훨씬 많아지게 된다. 또한 이미지의 공간적인 정보를 효과적으로 학습하기 어렵다. 왜냐하면 FCN을 사용한다고 가정했을 때, 이미지를 1차원 행렬로 flatten 해야 할 것인데, 이렇게 하면 이미지의 상하좌우 개념이 줄어즐게 된다.
하지만 CNN의 경우에는 계산량이 비교적 적다. 왜냐하면 커널의 크기/개수 만큼만 학습하면 되는 것이다. 입력 이미지가 들어왔을 때, 가중치가 공유되는 필터과 지역적인 이미지의 곱으로 연산되기 때문에 계산 효율이 좋다. 또한 이렇게 했을 때, FCN보다 공간적인 정보에 대한 학습이 더 잘 되며 이를 추출하여 Grad-CAM과 같이 모델이 어떤 부분을 집중해서 보는지 알 수 있게 된다. 입력층에 가까울수록 edge와 같은 저수준의 정보를 처리하며, 출력층에 가까울 수록 receptive field가 커지게 되면서 더 전체적인 정보를 처리할 수 있게 된다. 또한 패턴을 학습하기 좋다.
2. CNN 에서 'Receptive field' 는 무엇을 의미하는지 설명해주세요
receptive field는 cnn 계열 모델의 한 뉴런이 볼 수 있는 영역을 의미한다. 층이 깊어질 수록, 필터의 크기가 클 수록 receptive field의 크기가 커지게 된다. 이는 특정한 뉴런이 관찰할 수 있는 입력 데이터의 공간적 범위를 의미한다. 또한, 모델이 학습할 수 있는 공간적 정보의 범위를 의미하기도 한다. 충분한 크기의 receptive field가 있어야 모델이 이미지의 전체적인 이해를 할 수 있을 것이다.
3. 깊은 신경망은 기울기 소실 및 폭발에 대한 위험성을 가지고 있습니다. 1) 깊은 신경망에서도 기울기 소실, 폭발 문제를
최소화할 수 있는 방법으로 제안된 새로운 방법이 무엇인지 쓰고 2) 그 원리를 서술해주세요
딥러닝에서 기울기 소실이나 폭발과 같은 문제가 발생하는데, 이는 역전파가 진행될 때 생기게 된다. 대표적으로 활성화 함수로 sigmoid 함수를 사용하는 경우에 미분 값이 y * (1-y)가 되는데 이는 1보다 작은 값이다. 그렇기에 기울기 소실이 발생한다. 이러한 문제를 방지하기 위해서 다양한 활성화 함수가 제안 되는데 대표적으로 relu 활성화 함수가 있으며, 이는 y가 0보다 클 때, 기울기가 1 곱해지고, 0보다 작으면 0이 곱해진다. 그렇기에 이러한 기울기 소실 문제를 피할 수 있게 된다.
또 다른 방법으로는 skip connection을 이용하는 방법이 있다. 이 방식은 x = x + layer(x) 와 같은 형태로, 원본 정보를 그대로 더해서 넘겨주는 방식이다. 대표적으로 ResNet에서 제안된 방법이며, 개인적으로 LSTM도 이러한 방식과 유사하다고 생각된다 (아님 말고). 이렇게 하는 경우 계산 그래프를 생각해 봤을 때, layer(x)의 기울기가 0~1 사이더라도 정보가 소실되지 않고 유지시킬 수 있다.
4. Transformer의 Multi-head attention 은 구조 내에서 어떤 역할을 수행하는지 서술해주세요
우선 트랜스포머의 어텐션 구조는 크게 2가지로 나뉜다. self-attention & cross-attention이다. 전자는 인코더 부분에서 사용되고, 후자는 디코더 부분에서 사용된다. self-attention의 경우, 입력이 들어왔을 때, 그 입력을 3개로 분할하여 query, key, value로 사용된다. 이 때, query, key, value에는 서로 다른 projection layer가 곱해지는데, 이는 각 헤드마다 다르다. 즉, 동일한 입력에 대해서 헤드마다 query, key, value가 달라지는 것이다. 그렇게 한 후에 내적을 계산한다. 우선 query, key를 내적해서 attention score를 계산하게 된다. 그렇게 하면 각 문장에서 어떤 단어와 어떤 단어가 의미 있는지 배울 수 있게 된다. 이 때, 문법적인 관계도 배울 수 있고, 의미론적인 관계도 배울 수 있는데 그것은 헤드마다 다르다. 이를 다시 합쳐서 다음 layer로 진행된다. 멀티 헤드 어텐션 구조를 통해서 입력 데이터의 여러 관계를 학습할 수 있는 것이다. 즉, 다양한 표현 공간에서 다양한 정보를 추출하고 통합할 수 있는 것이다. 또한 병렬적으로 처리되기에 계산 효율이 좋다는 장점도 있다.
5. Transformer는 기존의 CNN, RNN 등과 어떤 점에서 다른지 human inductive bias 관점에서 설명해주세요
human inductive bias, 직역하면 인간의 귀납적인 편향을 의미한다. 귀납적인 것은 경험적인 것이라 생각한다. 즉, 인간이 의도한 편향이다. 어떤 모델을 설계할 때, 인간의 의도가 들어간다. 하지만 그것이 꼭 올바른 것일까? 아닐 수도 있다는 이야기이다.
CNN 계열의 모델은 패턴을 학습하는데 강점을 가진다. RNN 같은 모델은 시계열 데이터를 처리하는데 강점을 가진다. 하지만 Transformer의 경우 self-atttention 메커니즘을 통해서 스스로 데이터의 관계를 파악하는 모델이기 때문에 이러한 편향으로부터 조금은 자유롭고 인간이 모르는 다양한 패턴을 배울 수도 있다. 때문에 어떤 구조적인 가정을 최소화할 수 있다는 것이다.
6. positional embedding 이란 무엇인지 설명해주세요
트랜스포머 모델의 논문을 살펴보면, 사인-코사인 함수를 사용했다. 하지만, 최근에는 단순 임베딩 층을 사용해서 이를 구현한다. 코드 상에서 보면 인코더를 지난 벡터에 위치 임베딩 벡터를 더해주는 형태로 구현한다. 이는 학습 가능한 매개변수이다. 문장이 길어질 때, 문장이 어떤 위치에 있는지 중요하게 된다. 즉, 입력 데이터 내에서의 위치 정보를 넣어주는 것이다. 만약 이미지 처리라면, 패치된 입력 이미지끼리의 관계를 넣어줄 수 있게 되는 것이다. 그렇게 함으로써 입력 이미지간의 위치 관계를 고려하여 학습할 수 있을 것이다.
7. classification token은 어떤 역할을 수행하는지 설명해주세요
이는 CLS 토큰으로 잘 알려져 있는데, BERT 논문에서 처음 사용한 것으로 알고 있다. 이는 입력 데이터를 대표하는 값으로 생각할 수 있으며, 이를 통해서 분류를 할 수도 있고, 입력 데이터를 대표하는 값을 사용할 수 있다. 이는 전체적인 특징을 요약하는 벡터이다.
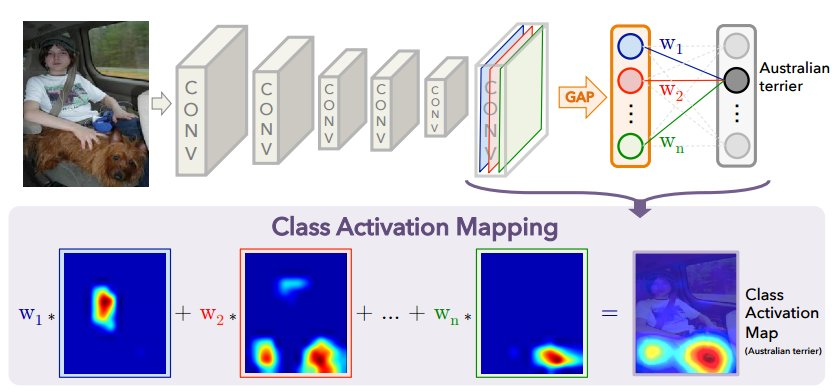
8. CAM(Class activation mapping) 에서 FC layer 대신 어떤 레이어를 사용하나요?
일단 CAM이 무엇인지 알아야 겠다. CAM은 설명 가능한 인공지능을만들기 위한 시도로 보인다. 이를 통해서 CNN 계열 모델이 입력 데이터의 어떤 부분을 집중하고 있는지 확인하는 것이다. 이 때, FC layer 대신에 Global Average Pooling을 사용한다. 이건 마지막 layer에 들어가게 되는데 cnn 모델을 생각해봤을 때, 여러 채널의 필터가 존재하는데 이를 합쳐주는 것이다. 각각의 필터가 주목한 곳이 다르고 이를 하나로 보기 위해서 사용하는 것이다. 이를 통해서 각 특징 맵을 공간 정보를 보존할 수 있는 것이다. 또한 각 피쳐 맵에서 선형 층을 사용하지 않고 풀링을 하면 계산이 훨씬 간단하다.
9. ViT 에서 CLS 토큰은 무엇인지 설명해주세요
일반적인 트랜스포머와 하는 역할은 크게 다르지 않으며, 이미지 전체에 대한 표현을 함축하고 있으며 이를 활용해서 분류 문제를 풀 수 있다.
10. Fully connected layer와 Fully convolutional layer의 차이를 서술해주세요
둘 다 줄임말이 FCN이라 헷갈리는데, 후자는 CNN만 사용한 모델이다. 그렇기에 계산이 더 효율적이라는 장점을 가지고 있고, 패턴을 더 잘 뽑아낸다. 또한 CNN 계열이기에 공간정보를 더 잘 이해한다. Fully convolutional layer는 처음부터 끝까지 합성곱 연산으로 이루어지기 때문에 이미지 -> 이미지 를 할 때 사용된다. 즉, segmentation을 할 때 사용하며, 대표적으로 unet 구조가 있다. 이들은 de-conv 연산을 수행하여, 이미지 정보를 작게 만들었다가 다시 복원하는 형태로 진행된다.
11. zero-shot과 few-shot에 대해 각각 설명해주세요
zero-shot은 예시를 보지 않고 문제를 푸는 것이다. zero-shot이 학습할 때와 추론할 때로 나뉘는거 같은데, 대부분의 모델이 학습할 때 zero-shot으로 한다. 예를 들어서, gpt한테 한번도 보지 못한 수학문제를 하나 던져 놓고 풀라고 하면 그건 zero-shot이고, 예제 문제를 몇 개 같이 주고 풀라고 하면 few-shot이 되는 것이다. 플라밍고와 같은 모델에서는 학습 파이프라인데 few-shot이 들어가는 것을 본 것 같기도 하다. 이것들의 장점은 추가적인 학습이 없을 때도, 효과적인 성능을 낼 수 있다는 것이다. 이런 것들이 통하는 이유는 트랜스포머 모델이 입력으로 부터 어떤 패턴을 배우기 때문이라고 해석된다.
12. Multimodal이란 무엇인지 설명해주세요
멀티모달이란 여러 모달리티, 여러가지 감각/정보 를 의미한다. 이미지와 텍스트를 같이 이해한다거나 하는 모델은 멀티모달 모델의 일종으로 vision-laguage model 이라고 부르기도 한다. 요즘은 audio 와 같은 정보들을 추가로 넣어주기도 한다.
13. CLIP은 어떤 원리로 동작하는지 설명해주세요
CLIP의 핵심이 되는 원리는 대조학습이다. 유사한 것은 벡터 공간 상에서 가까워지게 만들고, 서로 다른 것은 벡터 공간에서 멀어지게 만드는 기법이다. 이 때, 서로 관련된 이미지와 텍스트가 가까워지게 만드는 것이다. 즉, 이를 통해서 이미지와 텍스트를 같은 벡터 공간 상에 매핑하는 것이고, 이를 통해서 모델을 이미지와 텍스트의 유사도를 알 수 있게 되는 것이다.
14. VAE에 대해 설명해주세요
VAE는 변형 오토 인코더의 준말이다. 이는 확률적인 생성 모델을 만들기 위한 시도이다. 기존에 샘플링이 들어가게 된다면 이를 모델로 학습시키기 어렵다. 랜덤하게 샘플링 된 부분의 역전파를 진행시키기가 어렵기 때문이다. 하지만 이를 간단하게 해결했는데, 입력 x가 있을 때, 여기에 표준편차를 곱하고 평균을 더한다. 표준편차는 정규분포에서 나온 0~1 사이의 값과 곱하는 값이다. 즉, 샘플링은 따로 두고 그 값만 학습하겠다는 것이다.
아래 그림을 보면 잘 이해가 되는데, 잠재 벡터 z를 만들 때, 샘플링은 학습하지 않고, 평균과 표준편차만 학습 대상이 되는 것이고, 이를 decoder로 복원하는 것이다. decoder가 이미지라면, Transposed Convolutions 연산을 하면 되지 않을까 싶다.

이건 잘 이해가 안 돼서 GPT한테 코드 예시를 보여 달라고 했다.
인코더는 이런 식으로 input 데이터를 합축한 다음에 서로 다른 projection을 시켜준다.
역전파의 정보는 저 projection layer를 통해 전해지고 그렇게 함으로써 더 정확한 확률 공간을 만들어 낼 수 있는 것이다.
# Encoder
self.encoder = nn.Sequential(
nn.Linear(input_dim, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU()
)
# Latent space
self.fc_mu = nn.Linear(128, latent_dim) # Mean
self.fc_logvar = nn.Linear(128, latent_dim) # Log-variance
이제 이 mu와 logvar 정보를 가지고 잠재 벡터를 만들어준다.
def reparameterize(self, mu, logvar):
"""Samples z using the reparameterization trick."""
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std) # Random noise
return mu + eps * std
디코더는 저 압축된 벡터를 가지고 다시 복원하는 역할을 하는 것이다.
# Decoder
self.decoder_fc = nn.Sequential(
nn.Linear(latent_dim, 128),
nn.ReLU(),
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, input_dim),
nn.Sigmoid() # Assuming input is normalized [0, 1]
)
이렇게 하면 어떤 확률 분포를 만들고, 그 확률 분포로부터 데이터를 생성할 수 있게 되는 것이다.
얼굴 이미지로 학습을 하면 랜덤한 얼굴 이미지를 계속해서 뽑을 수 있는 것이다.
아니면 입력 이미지가 들어왔을 때, 이게 이 확률 분포에 맞는지 확인할 수도 있는 것이다.
아! 결국 이미지에 대한 확률분포를 알 수 있게 되고, 이 확률 분포로부터 이미지를 만들 수도 있어진 것이다.