
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 9020
- streamlit
- 파이싼
- 1002
- end to end
- 그리디 알고리즘
- pyenv
- 티스토리챌린지
- 4948
- 신경망 학습
- REST API
- 가상환경
- Retrieval
- 15649
- 밑바닥부터 시작하는 딥러닝
- 재귀
- 개발환경
- 백준
- BOJ
- 파이썬
- 오블완
- 경사하강법
- video retireval
- Python
- N-Queen
- 백트래킹
- 1101
- n과 m
- 기계학습
- 손실함수
Archives
- Today
- Total
파이톨치
LongVALE: Vision-Audio-Language-Event Benchmark Towards Time-Aware Omni-Modal Perception of Long Videos 본문
논문
LongVALE: Vision-Audio-Language-Event Benchmark Towards Time-Aware Omni-Modal Perception of Long Videos
파이톨치 2025. 4. 30. 17:12728x90
Motivation (동기):

이 연구는 기존의 비디오 이해 모델들이 visual-only 또는 coarse-grained 작업에 한정되어 있다는 한계를 극복하고자 하였습니다. 실제 영상에는 vision, audio, speech 정보가 복합적으로 존재하며, 이들을 종합적으로 처리해야만 진정한 비디오 이해가 가능합니다. 하지만 기존 데이터셋은 이런 복합적인 정보를 포함하는 fine-grained temporal annotations이 부족했습니다. LongVALE는 이런 문제를 해결하기 위해 다양한 omni-modal(시각, 음성, 언어) 정보를 포함하는 데이터셋을 제안합니다.
Methodology (방법론):
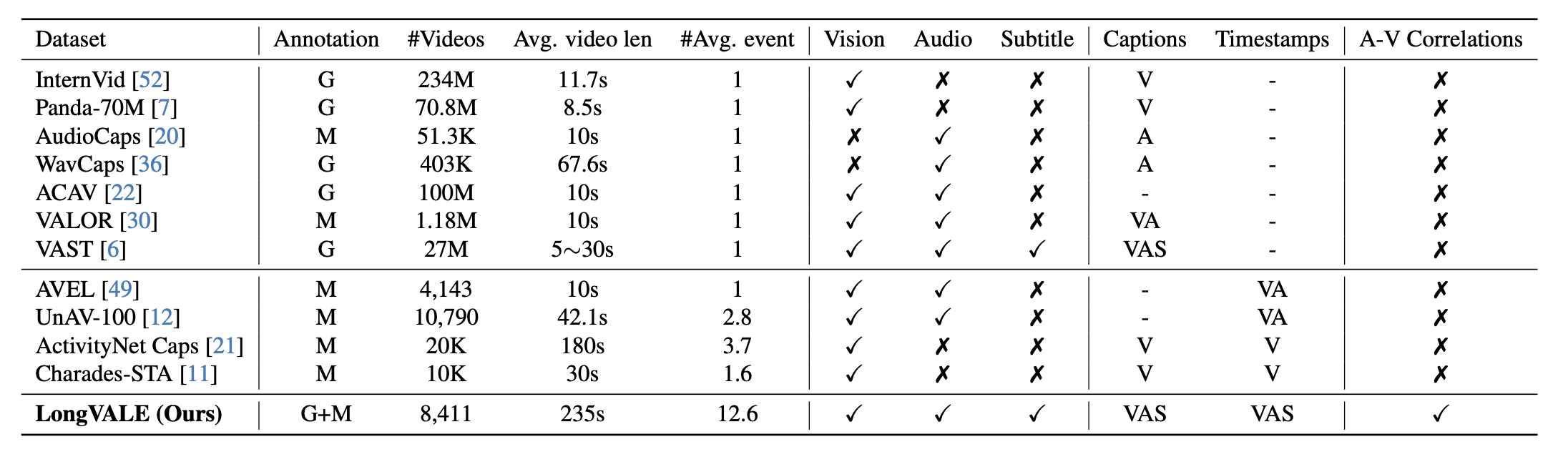

- Data Collection and Filtering (데이터 수집 및 필터링):
다양한 플랫폼에서 고품질 비디오를 수집하여, audio-visual semantics와 temporal dynamics가 풍부한 영상을 필터링하여 사용합니다. 이 필터링 과정은 scene changes와 audio-visual contrastive learning을 기반으로 하여 중요한 데이터를 추출합니다. - Event Boundary Detection (이벤트 경계 탐지):
기존의 비디오 분석 모델들은 visual boundaries만을 다루었지만, 본 연구에서는 omni-modal event boundaries를 제안하여 audio와 visual 모두를 고려한 경계를 설정합니다. 이렇게 하면 semantic coherence가 유지됩니다. - Event Captioning (이벤트 캡셔닝):
비디오 이벤트를 설명하는 캡션을 생성할 때, 기존의 단순한 caption concatenation이 아니라 audio-visual correlation reasoning을 통해 각 모달리티의 정보를 통합합니다. 예를 들어, audio 이벤트와 visual 이벤트의 상호작용을 고려하여 더 정확한 캡션을 생성합니다. - Modeling and Training (모델링 및 훈련):
LongVALE는 LongVALE-LLM, 즉 multi-modal video LLM을 구축하여 temporal video grounding, dense video captioning, segment captioning 등 복잡한 작업을 수행할 수 있게 합니다. 훈련 과정에서 boundary perception tuning과 instruction tuning을 통해 모델이 이벤트를 정확하게 이해하고, 인간의 지시를 따를 수 있도록 합니다.

Results (결과):
- LongVALE로 훈련된 모델은 omni-modal tasks(예: grounding, captioning, segment captioning)에서 기존 모델들보다 우수한 성능을 보였습니다.
- Zero-shot performance에서도 좋은 결과를 보였으며, audio-visual question answering (AVQA) 작업에서도 뛰어난 성능을 나타냈습니다.
- LongVALE 데이터셋은 cross-modal reasoning과 fine-grained temporal understanding을 향상시키는 데 중요한 역할을 합니다.
Ablation Studies (변수 분석):
- Audio-visual correlation reasoning이 포함된 모델이 성능이 크게 향상되었습니다.
- Modalities(시각, 음성, 언어)가 추가될수록 성능이 개선되었습니다. 모든 three modalities(vision, audio, speech)가 포함될 때 가장 좋은 성과를 보였습니다.
Conclusion (결론):
LongVALE는 omni-modality를 활용한 fine-grained video understanding의 새로운 기준을 제시합니다. 이 데이터셋과 모델은 cross-modal reasoning과 temporal understanding을 가능하게 하여 실제 비디오 분석에서 중요한 역할을 할 수 있습니다. LongVALE-LLM은 복잡한 멀티모달 작업을 처리하는 데 뛰어난 성능을 보여주며, 이 연구는 향후 omni-modal video understanding 분야에서 중요한 이정표가 될 것입니다.
728x90
'논문' 카테고리의 다른 글
'논문' Related Articles
more



