
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 재귀
- pyenv
- 백준
- 신경망 학습
- video retireval
- 1002
- 손실함수
- 오블완
- Python
- 1101
- BOJ
- 가상환경
- 15649
- 개발환경
- REST API
- 기계학습
- 티스토리챌린지
- 그리디 알고리즘
- 파이싼
- 백트래킹
- end to end
- streamlit
- 9020
- 밑바닥부터 시작하는 딥러닝
- 4948
- Retrieval
- 파이썬
- n과 m
- 경사하강법
- N-Queen
- Today
- Total
파이톨치
LONGVIDEOBENCH: A Benchmark for Long-context Interleaved Video-Language Understanding 본문
LONGVIDEOBENCH: A Benchmark for Long-context Interleaved Video-Language Understanding
파이톨치 2025. 5. 21. 15:11✅ 왜 이렇게 접근했는가? (동기)
문제의식:
기존 비디오-텍스트 벤치마크들은 대부분 짧은 비디오(수십 초~3분) 위주이고, 심지어 몇 개의 대표 프레임만으로도 풀 수 있는 문제들이 많아 실제 LMM의 "길고 복잡한" 입력 처리 능력을 평가하기엔 부족함.
- Single-frame bias: 모델이 많은 프레임을 보더라도 성능이 크게 개선되지 않음 → 장시간 맥락 이해를 필요로 하지 않기 때문.
- 텍스트 LLM과의 격차: 최근 GPT-4, Gemini 같은 LLM들은 128K 이상의 긴 컨텍스트를 이해할 수 있게 되었지만, 멀티모달 LMM에 대한 긴 컨텍스트 벤치마크는 거의 없음.
목표:
LMM이 1시간까지의 비디오 + 자막을 정밀하게 참조하고 복잡하게 추론할 수 있는지를 평가하는 새로운 벤치마크를 만들자.
🔍 어떻게 접근했는가? (방법)
핵심 설계: Referring Reasoning이라는 새로운 QA 과제 제안
- 질의문에 referring query가 포함되어 있음: 특정 장면, 자막, 객체 등을 "참조"하도록 유도
- 정답은 반드시 그 참조된 맥락(referred context)에서 추론되어야만 맞힐 수 있음
- Multiple-choice 형태로 구성 (정답 + 혼동 유도 distractors)
예시:
질문: “초반부, 붉은 옷과 검은 배낭을 멘 여성이 바위 언덕을 내려올 때, 배낭에 어떤 변화가 생기나요?”
→ 이건 "referring reasoning" 중 Object Attribute Change 유형임
🧠 어떤 방식으로 구성되었는가? (구체적 구성)
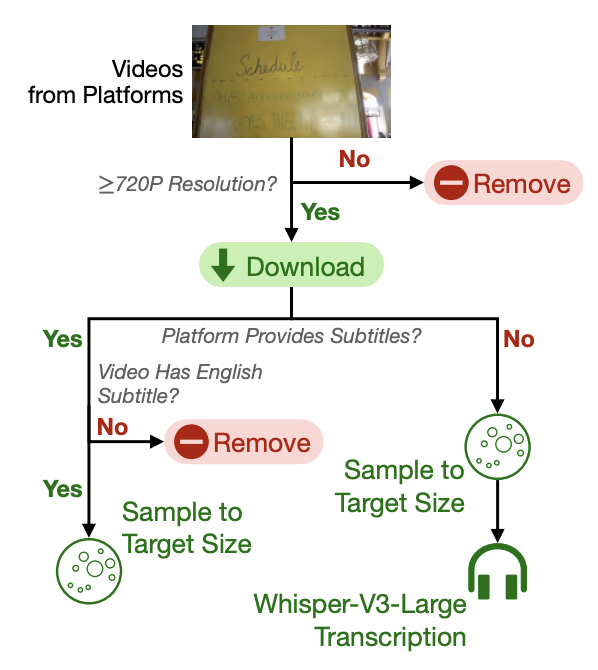
(1) 비디오-자막 데이터 수집
- 99개 채널에서 3,763개의 비디오 수집
- 자막 미포함 비디오는 Whisper-V3로 자동 전사
- 전처리 후 품질(Q-Align 점수) 기준으로 필터링
(2) 질문 설계
- 총 6,678개의 multiple-choice 문제 생성
- 질문마다 referring query와 질문 본문이 포함됨
- 길이대별(8~3600초), 주제별(일상, 영화, 뉴스, 지식)로 다양하게 분포
- 17개 세부 유형으로 분류됨:
| (L1) Perception | 단일 장면 내의 객체/행동 이해 | “붓으로 노란 액체를 바르고 있던 음식은 무엇인가?” |
| (L2) Relation | 복수 장면 간의 관계 추론 | “이 장면 이후에 여성이 한 행동은 무엇인가?” |
(1) 긴 입력을 처리할 수 있을수록 성능 향상
- GPT-4o, Gemini-1.5-Pro 등은 input frame 수가 늘어날수록 정확도가 확연히 증가함
→ (900~3600초) 비디오에서 GPT-4o는 36% → 66.7%로 향상
(2) 오픈소스 모델은 성능 향상 거의 없음
- IDEFICS2, MANTIS 등은 frame 수 늘리면 오히려 정확도 하락
→ 긴 입력 처리 및 통합 능력 부족
(3) Relation(L2) 질문이 더 어려움
- 특히 Sequence of Scenes (SSS) 항목이 가장 낮은 정확도를 보임
→ 장면 간 순서 추론에 약함
(4) Referring Query의 거리 영향을 받음
- 질문에서 참조된 장면이 비디오 초반 또는 중간일수록 모델 성능 하락
→ Query-to-Context 거리 문제 발생
🔎 예시 기반 설명
예시 1: (L1) Scene-referred Event
“왼쪽 상단에 ‘wanna make a meaningful connection’이 적힌 장면에서, 하얀 하트 무늬 옷을 입은 남성은 무엇을 하고 있는가?”
→ 이 문제는 시각적 세부사항 인식 + 특정 장면 recall이 필요함
예시 2: (L2) Sequence of Scenes
“사진첩 장면 → 만화쥐 그림 → 앱 아이콘 장면 순이 맞는가?”
→ 단순 frame-level 인식이 아니라 복수 장면 간 시간 순서 이해가 필요함
⚠️ 어떤 한계가 있는가?
- Annotation 비용: 모든 질문은 사람이 직접 보고 작성 + 검토 + 수정 → 대규모 생성에는 시간과 비용이 큼
- Latency 이슈: Referring query가 중간 또는 초반에 있는 경우, 모델은 더 긴 컨텍스트 추론이 필요해 연산량 증가
- 모델 훈련 데이터와의 도메인 차이: LONGVIDEOBENCH는 자막이 많은 생활/지식 영상 기반인데, 기존 LMM은 짧은 영상이나 이미지 중심 훈련으로 성능 저하
- (L2) Relation 질문 한계: 현재 모델들이 Temporal Reasoning (시점 간 관계)에서 전반적으로 약함 → 연구 필요성 강조
🏁 요약
LONGVIDEOBENCH는 LMM의 진짜 실력을 보기 위한 리얼리티 체크이다.
Referring reasoning이라는 강제적인 맥락 추론 기반 QA를 통해, 단순 요약이 아닌 복잡한 장면 이해 및 관계 추론을 요구한다. GPT-4o 같은 최신 모델조차도 중간/후반 referring query에서는 성능 저하가 발생하며, open-source 모델들은 아예 input 길이에 따른 이득조차 없다. → 향후 긴 컨텍스트 멀티모달 모델의 개선 방향성을 제공한다.
