
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- pyenv
- 티스토리챌린지
- 그리디 알고리즘
- 파이싼
- 백준
- 1101
- 가상환경
- 1002
- 밑바닥부터 시작하는 딥러닝
- 손실함수
- 경사하강법
- Retrieval
- 개발환경
- video retireval
- BOJ
- 9020
- 재귀
- REST API
- streamlit
- 오블완
- 15649
- end to end
- 기계학습
- Python
- n과 m
- 백트래킹
- 파이썬
- 신경망 학습
- N-Queen
- 4948
- Today
- Total
파이톨치
Omni Captioning Papers 본문
Omni Captioning Papers
AVoCaDO
AVoCaDO는 영상+오디오(AV)를 시간적으로 맞물리게(temporal orchestration) 서술하는 캡셔닝 모델. 107K AV 캡션 SFT와 GRPO 보상 3종(체크리스트, 대화 정확도, 길이 정규화)로 학습해, 여러 AV 캡셔닝 벤치마크에서 오픈소스 SOTA 및 일부 상용 모델 수준까지 도달.

문제의식 & 아이디어
- 기존 비디오 캡셔닝은 비전 중심이라 오디오(대사, 효과음, 음악) 정보와 시점 정합을 놓침.
- 단순히 “비디오 설명 + 오디오 설명을 이어붙이기”는 시간적 대응 실패 → QA 성능 저하.
- 파일럿 실험: 공동 처리(AV joint caption)가 분리 후 연결 대비 +15.8%, 특히 AV 이벤트 정합 과제에서 +27.8% 향상. → AV 동시·정합 캡션이 성능의 핵심.

모델/학습 파이프라인
- 베이스: Qwen2.5-Omni-7B(영상 프레임·오디오를 교차 토큰열로 정렬 가능).
- AVoCaDO SFT (감독 미세조정)
- 데이터 107K AV 캡션 쌍 자체 구축.
- 두 단계 캡션 제작: (1) 비디오/오디오를 각각 캡션화 → (2) 원본 영상과 함께 시간 정합된 단일 AV 캡션으로 재합성.
- 품질 필터링: 길이/중복 제거 후, 합성 전·후 캡션을 GPT-4.1로 완결성 1–5점 평가, 4점 이상만 채택.
- 소스 구성 예시: TikTok-10M(24K), ShortVideo(18K), Shot2Story(20K), FineVideo(29K), YouTube-Commons(11K), CinePile(5K).
- AVoCaDO GRPO (강화 후처리)
- GRPO로 2K 샘플에 보상 최적화.
- 보상 3종
- 체크리스트 기반(RC): AV 캡션을 5축(교차모달 내러티브/동작·상호작용/오디오 요소/시공간·촬영/정적 엔티티) 키포인트로 분해, 키포인트 충족률 보상.
- 대화 기반(RD): 모델 캡션에서 대사 추출 후, 내용 유사도(편집거리, LCS, 임계 0.6) + 화자 일치로 F1 산출·보상.
- 길이 정규화(RL): 토큰 길이 τ1=2048, τ2=4096 구간으로 과도한 장문/반복 붕괴 억제.
- 최종 보상 R = RC + RD + RL.
- 구현/세부셋팅(요지)
- SFT: 2 epoch, bs=128, lr=2e-5. / GRPO: 1 epoch, bs=64, lr=1e-5, 샘플 8개, KL 계수 0.04.
- 비디오 2fps 샘플링, 프레임 해상도 제한, 컨텍스트 32K 내 토큰 한도 관리.
- 비디오/오디오 인코더 고정, 어댑터+LLM만 업데이트.
평가 & 결과(요지)
- AV 캡셔닝(직접 평가): Gemini-2.5-Pro/Flash, InternVL3.5(V 전용), Qwen2.5-VL(V), HumanOmniV2(7B), ARC-Hunyuan-Video(7B), MiniCPM-o-2.6(8B), Qwen2.5-Omni(7B), video-SALMONN-2(7B), UGC-VideoCaptioner(3B), Qwen3-Omni-Instruct/Captioner(30B-A3B). 결과는 공식 코드로 재현해 비교함.
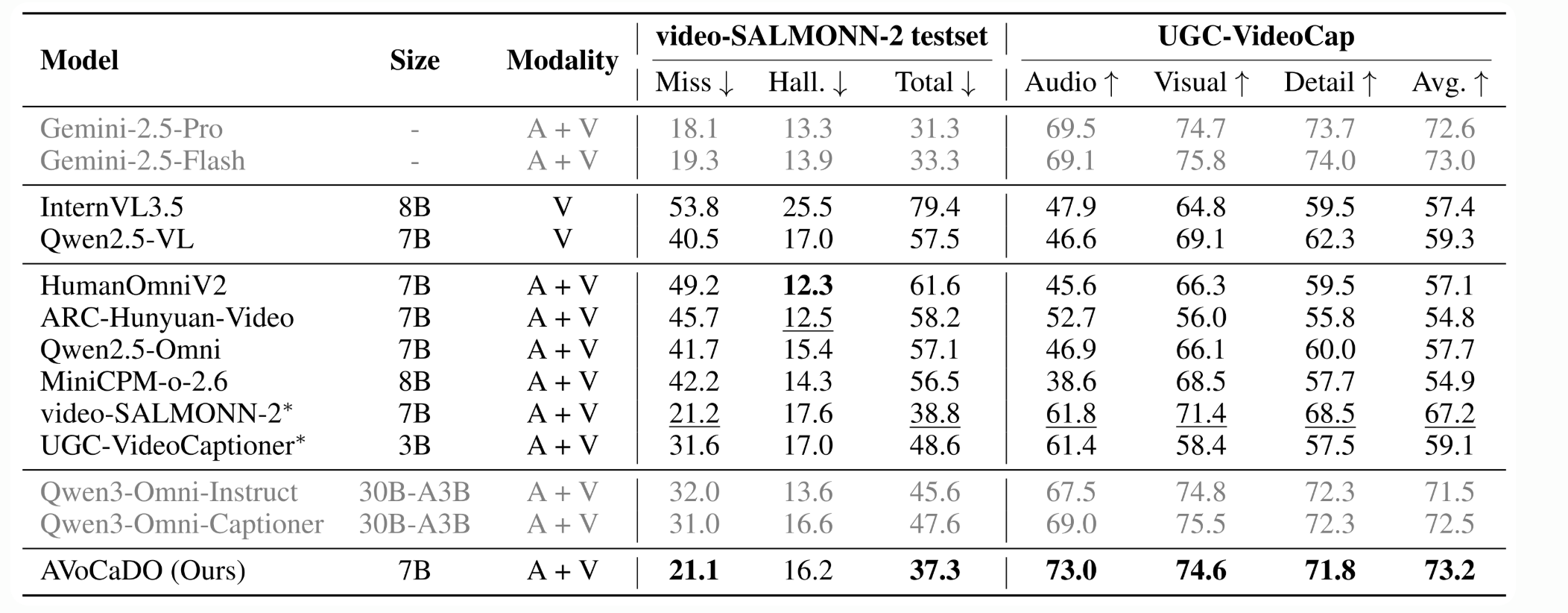
- 벤치마크: video-SALMONN-2 testset, UGC-VideoCap, Daily-Omni, WorldSense, 그리고 시각 전용 VDC-Detailed, DREAM-1K.
- 직접 캡션 평가
- video-SALMONN-2: Total 에러율 최소화, 오픈소스 중 SOTA.
- UGC-VideoCap: Avg 73.2로, 최신 오픈소스 및 일부 상용 대비 경쟁력/우위.
- QA로 간접 평가(캡션만 보고 답)
- Daily-Omni: 50.1%, WorldSense: 25.7%로 동급 대비 큰 폭 우세.
- 시각 전용
- VDC-Detailed Acc 47.4 / VDCscore 2.5, DREAM-1K F1 35.9로 비전만 평가에서도 경쟁력 확인.
- Ablation
- RD 추가 시 대화 F1 +2%p 내외 향상, RL로 반복 붕괴율 대폭 감소(예: 2.4%→0.4%).
- 동일 2K로 SFT만 더 돌리면 큰 이득 없음 → 보상 설계 자체의 기여 확인.
기여 포인트
- 시간 정합된 AV 캡셔닝에 특화된 SFT+RL 파이프라인 설계.
- 대사 정확도/화자 일치를 직접 겨냥하는 대화 보상 도입.
- 짧은 UGC~멀티샷/시네마틱까지 아우르는 고품질 107K 데이터 공개 예고(오픈소스화).
한계 & 코멘트
- 생성·판정에 상용 LLM 의존(Gemini, GPT-4.1) → 데이터/보상의 모델 편향 가능성.
- 트레이닝 2fps/32K 한계로 초장편·고밀도 AV 커버리지 제약.
- QA-by-caption은 심판 모델 의존적 평가(정답 거부 지침 포함) → 절대치 해석 주의.
당신 연구에 쓸 포인트(힌트)
- AV 정합 캡션을 후속 태스크(검색/그라운딩/요약)의 중간 표현으로 사용.
- 댓글·자막 기반 대화 F1-류 보상을 그대로 모멘트 리트리벌의 텍스트 정밀도 측정에 응용 가능.
- 체크리스트 보상의 5축 분류는 데이터셋 라벨 프레임으로도 유용.
OmniVideoBench
OmniVideoBench는 길게는 30분짜리 실영상까지 포함해 오디오+비디오를 함께 이해해야만 풀 수 있는 객관식(MCQ) QA 1,000문항과 단계별 추론 트레이스로 구성된 AV 협력 추론 벤치마크. 최신 폐쇄형 모델조차 60% 미만 정답률에 머물러 음악·장기 영상·교차모달 추론의 난점을 드러냄.

왜 만들었나 (문제의식)
- 기존 벤치마크는 비전 편향 혹은 단일 모달로도 풀리는 문제가 많아, 실제 AV 상호보완 추론 능력을 측정하기 어려움.
- 특히 장기 시간 의존성, 음성·환경음·음악 같은 오디오 단서의 활용을 제대로 평가하지 못함.
어떻게 만들었나 (파이프라인/설계)

- 영상 수집: 유튜브·빌리빌리에서 628개 실영상(최소 480p, 수초~30분)을 8대 장르/68개 세부 카테고리로 균형 있게 선별. 자막 오버레이·중복 데이터는 배제.
- 문항 구성: 1,000개 QA를 13개 과제 유형(시공간 추론, 인과, 카운팅, 배경·음악 이해 등)으로 작성하고, 단계별 추론 체인(모달리티·증거·추론)을 인력으로 부착.
- 품질 보증:
- Unimodal 필터링: Gemini-2.0/2.5-Flash로 단일 모달만으로 풀리는 문항 제거.
- 텍스트 편향 제거: DeepSeek-V3.1로 옵션/문장 단서만으로 답 가능한 문항 수정/삭제.
- 최종 수기 검수: 정답 유일성·정확성 재확인 후 원자적(atomic) 추론 스텝으로 정제.
데이터 통계 (요지)
- 평균 길이 ~384초(6.4분), 해상도 최소 480p.
- QA 1,000개, 질문 평균 14.7단어, 정답 평균 4.9단어, 추론 스텝 평균 5.68개(비전 54%·오디오 46%).
- 오디오 유형 분포: Speech 762 / Sound 147 / Music 91.
벤치마크 특성/비교

- 기존 AV-Odyssey·OmniBench 등 이미지 기반 또는 짧은 클립 중심 평가 대비, OmniVideoBench는 수초~30분 실영상을 다루며 도메인 다양성과 오디오 유형을 폭넓게 포함.
- 동일 조건에서 Qwen2.5-Omni-7B가 OmniVideoBench에선 29.3%로 랜덤 수준에 가깝고, 기존 일상형 벤치마크 대비 난도가 훨씬 높음.
주요 결과 (하이라이트)
- 최고 성능: Gemini-2.5-Pro 58.90%. 그 외 다수 모델은 50% 미만, 오픈소스는 대체로 랜덤 근처.
- 오디오 유형별 난이도: Music이 최난(예: Gemini-2.5-Pro 38.46%), Speech > Sound > Music 순으로 쉬움.
- 길이 효과: **프레임 샘플 수(32→256)**를 늘리면 전반적으로 정확도 상승, 장기 영상일수록 이득 큼.
- ASR의 역할: 비전 전용/약한 Omni 모델에서 Visual+ASR > Visual Only, 하지만 ASR만으로 대체 불가(음악·비언어적 사운드 과제는 여전히 취약).
- 형식 효과: 오픈엔드 QA는 MCQ 대비 큰 폭 성능 하락 → 정답 옵션 단서에 기대는 경향을 드러냄.
무엇을 측정하나 (13개 과제 예)
Fine-grained Perception, Spatial/Temporal Reasoning, Counting, Causal/Relationship/Referential Reasoning, Summarization, Sentiment, Ego, Background & Music Understanding 등. 특히 배경·음악 이해가 모든 모델에 가장 어려움.
한계/주의
- 수기 제작 비용↑: 고품질이지만 생성·검수에 인력 의존.
- 최근 공개 영상 위주 선택으로 도메인 분포 편향 가능.
- MCQ 중심 지표는 실사용 오픈엔드 질의 난도를 과소추정할 수 있어, 양쪽 지표를 함께 볼 것.
너의 연구에 바로 쓰는 팁
- 롱비디오 멀티모달 평가 세트로 채택: 네가 만드는 댓글·모달리티 게이팅 기반 모멘트 리트리벌이 실제 AV 협력 추론을 개선하는지 OmniVideoBench로 검증.
- 세팅 권장:
- 입력 프레임 ≥128(가능하면 256) + 원본 오디오 포함.
- 비전전용 베이스라인에는 ASR 텍스트 추가도 함께 보고(단, 음악/배경음 과제 한계 명시).
- 길이별 성능 곡선(≤1, 1–5, 5–10, 10–30분)과 오디오 유형별(Speech/Sound/Music) 브레이크다운을 함께 보고서에 포함.
- 분석 포인트: 실패 케이스 중 음악 주도, 장면 전환 잦은 장기 영상, 관계/인과 추론에서의 오답 패턴을 사례로 제시하면 설득력↑.
AN EMPIRICAL STUDY FOR REPRESENTATIONS OF VIDEOS IN VIDEO QUESTION ANSWERING VIA MLLMS
VideoQA에서 무엇을 입력(자막·프레임·오디오)으로 넣느냐가 정확도·VRAM·지연시간을 크게 좌우한다. 자막(S)은 가볍고 특히 롱비디오에서 효과적, 프레임(V)은 정확도↑지만 비용(메모리·시간) 최댓값, S+V 조합이 대체로 최고 성능.
무엇을 했나
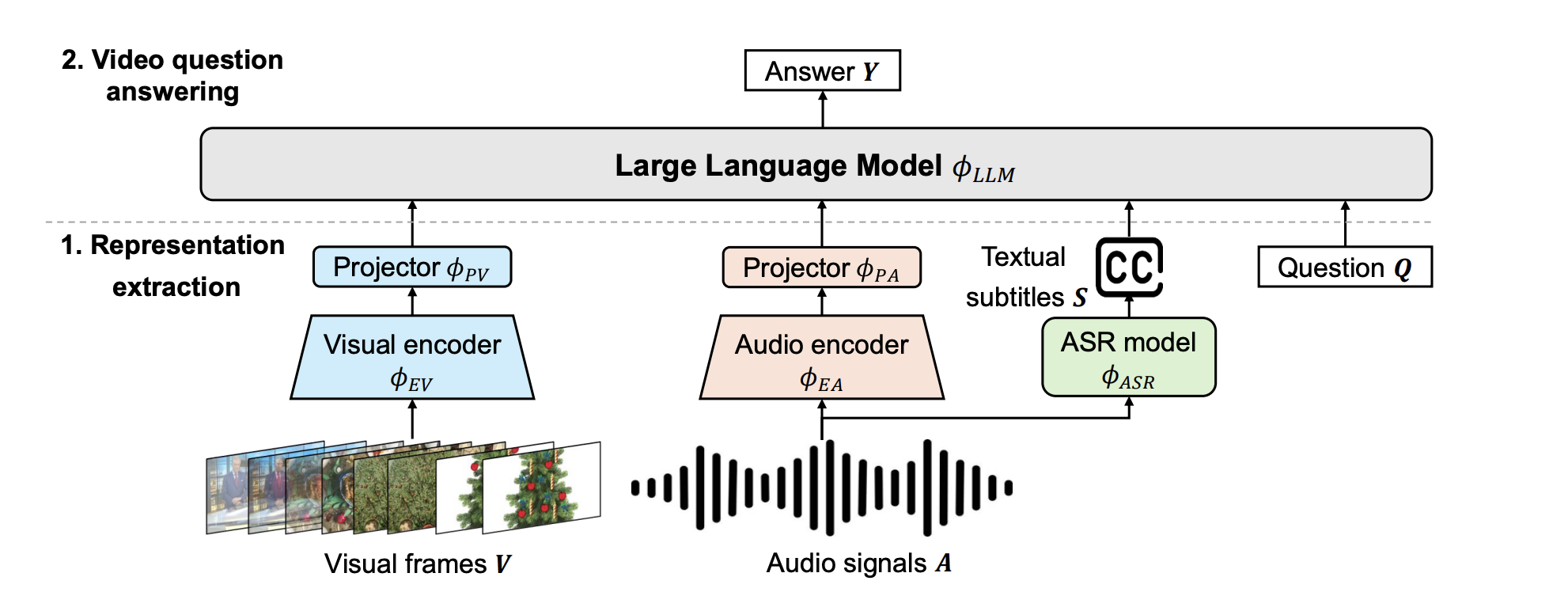

- 벤치마크: VideoMME, LongVideoBench(Val.).
- 모델: LLaVA-video 7B/72B, Qwen2.5-VL 7B/72B, video-SALMONN-2 (7B/72B, +변형).
- 입력 조합 비교: Q, Q+S, Q+V, Q+S+V, (SALMONN 계열은 Q+A+V).
- 자막 파이프라인: VAD(WebRTC)로 구간 → Whisper-Large-v3로 ASR.
주요 결과
- 정확도
- 롱비디오(특히 VideoMME의 long 구간)에서는 자막(S)이 프레임(V)보다 효과적.
- S+V가 대부분의 경우 최고. A+V보다 S+V가 Qwen2.5-VL에서 ~3.6–3.7%p 높음.
- 질문만(Q)도 랜덤 대비 7B≥+15%p / 72B≥+20%p(상식 지식 효과).
- 효율성
- VRAM·지연시간의 병목은 프레임(V). 7B에서도 메모리 거의 2배 수준, 지연은 시간 단위까지 증가.
- 자막(S) 추가는 오버헤드 미미.
- 종합 결론: S는 가벼운 강점, V는 비싸지만 성능 견인, S+V가 베스트 프랙티스. 오디오는 보완적이나, 모든 모델에 필수는 아님.