
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 신경망 학습
- 그리디 알고리즘
- 파이싼
- BOJ
- 가상환경
- 1002
- 손실함수
- 밑바닥부터 시작하는 딥러닝
- 백트래킹
- 9020
- 경사하강법
- 1101
- 4948
- 티스토리챌린지
- video retireval
- N-Queen
- 개발환경
- REST API
- 재귀
- 기계학습
- 오블완
- pyenv
- 백준
- Retrieval
- streamlit
- 15649
- Python
- n과 m
- end to end
- 파이썬
- Today
- Total
파이톨치
[Linear Algebra] 대학원 면접 대비 선형 대수 헷갈리는 내용 정리 본문
Linear Algebra
Determinant
Determinant는 정사각행렬에 붙는 하나의 스칼라 값이고 그 값은 선형변환이 공간을 얼마나 늘리거나 줄이는지 그리고 방향을 뒤집는지까지 함께 담는다. 이 관점만 잡히면 공식이 많아 보여도 한 줄로 정리된다. Determinant는 부피의 배율과 방향 정보를 주는 값이다.
가장 직관적인 정의는 선형변환 A가 R^n의 한 영역을 다른 영역으로 보낼 때 n차원 부피가 얼마나 변하는지를 보는 것이다. 단위 정육면체의 부피는 1인데 이를 A로 보내면 어떤 평행육면체가 되고 그 부피가 ∣det(A)∣가 된다.
그리고 부호는 방향을 말한다. 방향이 보존되면 양수이고 뒤집히면 음수다. 이 한 문장이 det의 거의 모든 성질을 자연스럽게 설명한다.

두 열벡터가 만드는 평행사변형 넓이가 ad−bc로 계산되기 때문이다.
ad는 직사각형 성분이고 bc는 겹쳐서 빠져야 하는 전단 성분이라고 보면 된다.

조금 더 구조적인 정의로 가면 determinant는 다음 성질을 만족하는 유일한 함수라고 볼 수 있다. 입력은 열벡터 v1,…,vn이고 출력은 실수이며 각 슬롯에 대해 선형이고 같은 벡터가 두 번 들어가면 값이 0이 되며 벡터 둘을 바꾸면 부호가 바뀐다.
마지막으로 표준기저 e1,…,en를 넣었을 때 값이 1이 되도록 정규화한다. 이 조건들이 곧 부피라는 성질을 강제한다. 선형성은 한 변을 늘리면 부피가 비례해서 늘어야 한다는 뜻이고 두 벡터가 같으면 납작해져서 부피가 0이라는 뜻이며 교환 시 부호 변화는 방향 개념을 강제한다. 이 관점은 외워야 할 공식 대신 왜 그런지가 남는다.
이 정의에서 바로 튀어나오는 핵심 성질들이 있다. 먼저 det(AB)=det(A)det(B)가 된다. 선형변환을 두 번 적용하면 부피 배율도 두 번 곱해지기 때문이다. 그래서 역행렬이 있으면 det(A−1)=1/det(A)가 된다. 또 det(A)=0이면 부피가 0이므로 어떤 차원으로 납작해졌다는 뜻이고 그래서 A는 일대일이 아니며 역행렬이 없다. 반대로 det(A)≠0이면 부피가 0이 아니고 납작해지지 않으니 역행렬이 존재한다. “가역성은 det가 0이 아닌 것과 동치”라는 문장이 이렇게 나온다.
행 연산과의 관계도 부피 관점에서 바로 이해된다. 한 행을 다른 행에 더하는 것은 전단 변화라서 부피를 바꾸지 않으니 det는 그대로다. 두 행을 바꾸면 방향이 뒤집히니 부호가 바뀐다. 한 행을 k배 하면 그 방향으로 길이가 배가 되니 부피도 k배가 된다. 그래서 가우스 소거로 삼각행렬을 만들고 대각 원소를 곱하면 det를 쉽게 구할 수 있다. 실제 계산은 이 방식이 기본이다.
라플라스 전개라는 것도 있다. 한 행이나 한 열을 기준으로 작은 행렬의 determinant를 재귀적으로 묶는 방식인데 구조를 보기에는 좋지만 큰 행렬 계산에는 비효율적이다. 대신 소거법이나 LU분해가 계산의 표준이다. A=LU이고 L의 대각이 1로 잡히면 det(A)=det(L)det(U)가 된다.
고유값과도 깔끔하게 연결된다. AA의 고유값이 λ1,…,λn이면 중복을 포함해 가 된다.
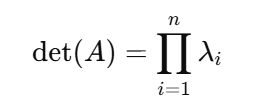
이는 선형변환이 어떤 축 방향으로는 λi만큼 늘리고 줄인다는 해석과 맞닿아 있다.
Diagonal matrix
대각행렬은 계산이 쉬운 특수한 행렬이 아니라 좌표축마다 서로 간섭하지 않는 선형작용의 가장 순수한 형태다. 어떤 벡터를 넣어도 각 성분은 자기 자리에서만 스케일이 바뀌고 다른 성분으로 섞이지 않는다. 그래서 대각행렬을 이해한다는 것은 선형변환이 섞임을 만들 때 무엇이 본질이고 무엇이 좌표계의 선택인지 가르는 감각을 얻는 일과 같다.
대각행렬을 하나의 함수로 보는 관점이 유용하다. D=diag(d1,…,dn)는 벡터 x의 i번째 성분에 di를 곱하는 연산자다. 이때 D의 덧셈은 함수값의 덧셈과 같고 D의 곱셈은 성분별 곱과 같다. 즉 대각행렬들의 집합은 서로 교환하는 대수이며 실제로는 R^n에 있는 값들의 모음과 같은 구조를 가진다. 이 관점에서 대각행렬은 선형대수의 대상이라기보다 좌표축 위에 값을 붙인 신호이자 좌표별 가중치 맵이다.
이 구조를 더 선명하게 보려면 표준기저 방향의 투영을 꺼내면 된다. Pi=eiei⊤는 i번째 성분만 남기는 투영이고 이 투영들은 서로 곱하면 0이 되며 합치면 항등이 된다. 그러면
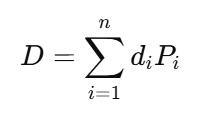
로 쓸 수 있다. 여기서 중요한 점은 가 값 di와 분해 조각 Pi의 조합이라는 사실이다. di 값은 스케일을 뜻하고 Pi는 어느 부분공간이 독립적으로 움직이는지를 뜻한다. 이 형태는 대각행렬에서 끝나지 않고 정상행렬의 스펙트럴 분해와 같은 큰 틀로 그대로 이어진다. 대각행렬은 스펙트럴 사고의 가장 단순한 표본이다.
대각화가 왜 강력한지도 같은 언어로 정리된다. 어떤 행렬 A를 A=SDS^-1 만들었다는 말은 A가 어떤 좌표계에서는 성분들이 서로 섞이지 않도록 보인다는 뜻이다. 여기서 는 좋은 좌표계를 고르는 역할을 하고 D는 그 좌표계에서의 순수한 작동 규칙을 담는다. 그래서 대각화는 복잡한 선형작용을 좌표별 스케일로 바꾸는 과정이며 문제를 섞임이 없는 형태로 바꾸는 과정이다.
대각행렬을 중심으로 보면 고유값과 고유벡터도 새로운 느낌으로 연결된다. 대각행렬의 고유벡터는 표준기저이고 고유값은 대각 원소다. 일반 행렬에서 고유벡터를 찾는다는 것은 표준기저 같은 역할을 하는 축을 다시 찾는 일이며 고유값은 그 축에서의 스케일이다. 즉 고유분해는 대각행렬이 가진 구조를 일반 행렬로 옮기려는 시도다.
Diagonalization of a Matrix
행렬의 diagonalization은 계산 트릭이 아니라 선형변환을 “섞임이 없는 좌표계”로 옮기는 작업이다. 어떤 행렬 가 A=SDS^-1로 표현된다는 말은 S가 좌표계를 바꾸는 변환이고 가 그 좌표계에서의 순수한 작동 규칙이라는 뜻이다.
원래 좌표계에서는 한 번의 적용이 여러 축을 섞어 버리지만 고유벡터 좌표계에서는 각 축이 독립적으로 스케일만 바뀐다. 이때 diagonalization은 “혼합”을 “성분별 스케일”로 환원하는 해석 장치다.
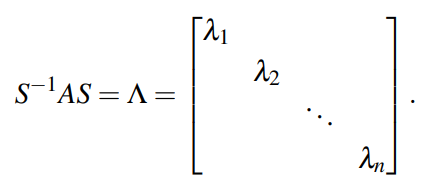
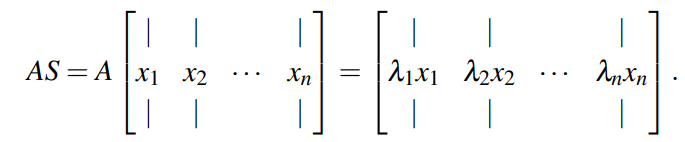
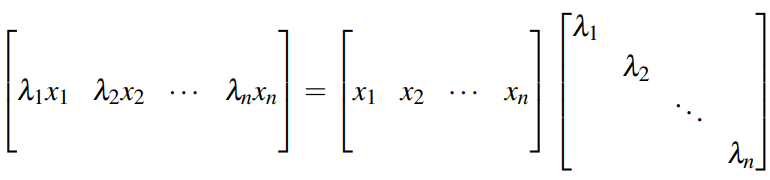
행렬의 대각화는 선형변환이 만드는 섞임을 없애고 각 방향이 독립적으로 늘고 줄도록 좌표계를 바꾸는 작업이다. 어떤 행렬 가 A=PDP−1로 쓸 수 있으면 는 대각행렬이고 의 열벡터들은 A의 고유벡터들이다. 이 표현이 뜻하는 바는 단순하다. 원래 좌표계에서는 를 한 번 적용할 때 여러 성분이 섞이지만 고유벡터 좌표계에서는 성분이 서로 섞이지 않고 각 성분이 자기 고유값만큼 곱해진다. (축은 그대로인데, A로 선형변환을 해도 길이만 바뀌는 것임!!!)
기본 정의부터 정리하겠다. v≠0와 λ가 Av=λv를 만족하면 를 고유벡터라 하고 λ를 고유값이라 한다. 고유벡터는 변환을 거쳐도 방향이 바뀌지 않는 축이다. 고유값은 그 축에서의 배율이다. 대각화가 된다는 것은 이런 축이 공간 전체를 채울 만큼 충분히 많다는 뜻이다. 정확히는 서로 독립인 고유벡터가 개 있으면 n×n행렬 A는 대각화 가능하다.
대각화의 핵심 조건은 고유값의 개수보다 고유공간의 크기다. 같은 고유값이 여러 번 등장해도 대각화가 될 수 있다. 대신 그 고유값에 대응하는 고유벡터가 충분히 많이 나와야 한다. 이를 직관으로 말하면 한 배율이 여러 축에 동시에 적용될 수는 있지만 그 축 자체는 여전히 여러 개여야 한다. 어떤 고유값에 대해 고유벡터가 부족하면 그 부족한 만큼 섞임이 남고 그러면 대각화가 깨진다.
실제로 대각화를 구하는 과정은 다음 흐름으로 이해하면 된다. 먼저 det(A−λI)=0을 풀어 고유값을 찾는다. 다음으로 각 고유값 λ마다 (A−λI)v=0을 풀어 고유벡터들을 구한다. 마지막으로 독립인 고유벡터들을 모아서 를 만들고 그 순서에 맞춰 의 대각에 고유값을 놓는다. 이때 P가 가역이면 A=PDP^-1가 성립한다.
대각화가 주는 가장 직접적인 이득은 반복 적용이 쉬워진다는 점이다. A^k = P D^k P^{-1}가 되며 D^k는 대각 원소를 제곱하면 끝난다. 그래서 긴 시간의 거동을 고유값의 크기로 바로 읽을 수 있다. ∣λ∣<1인 성분은 반복할수록 사라지고 ∣λ∣> 1인 성분은 커지며 ∣λ∣=1인 성분은 유지되거나 진동한다. 이 관점은 선형 동역학과 마코프 연쇄와 반복 알고리즘의 수렴을 해석하는 데 그대로 쓰인다.

Invertible & Diagonalizable & Not diagonalizable
(a) invertible 이다
가 invertible 이려면 det(A)≠0이어야 한다. 이는 0이 고유값이 아니라는 것과 같고 따라서 rank(A)=n이며 A^{-1}가 존재한다는 뜻이다.
(b) diagonalizable 이다
A가 diagonalizable 이려면 선형독립인 고유벡터가 개 존재해야 한다. 같은 말로는 모든 고유값 λ에 대해 그 고유공간의 차원들의 합이 nn이 되어야 한다. 여기서 각 고유값에 대해 기하적 중복도는 대수적 중복도보다 크지 않으므로 모든 λ에서 기하적 중복도와 대수적 중복도가 일치하면 diagonalizable 이다. 충분조건으로는 고유값이 모두 서로 다르면 항상 diagonalizable 이다. 또 실대칭 행렬은 항상 diagonalizable 이고 더 강하게 직교대각화가 된다.
(c) not diagonalizable 이다
가 not diagonalizable 이려면 선형독립인 고유벡터의 개수가 보다 작아야 한다. 즉 어떤 고유값 λ에 대해 고유공간의 차원이 그 고유값의 대수적 중복도보다 작으면 대각화가 불가능하다. 실무적으로는 중복 고유값이 존재하고 그에 대응하는 고유벡터가 충분히 나오지 않는 경우에 발생한다. 이때는 조르당 블록이 생기며 대각선 밖의 항이 0으로 사라지지 않는다.
Singular Value Decomposition
SVD는 임의의 직사각행렬을 회전과 스케일의 조합으로 분해하는 방법이다. 행렬이 어떤 벡터를 어떻게 바꾸는지 가장 깔끔하게 드러내는 표현이라서 선형대수의 핵심 도구로 자주 쓴다.

여기서 A는 m×n행렬이고 는 m×m 직교행렬이며 V는 n×n 직교행렬이다. Σ는 m×n 대각 형태의 행렬이고 대각 성분은 σ1 ≥ σ2 ≥ ⋯ ≥ 0인 값들이다. 이 σi를 singular value라고 부른다.

이 식이 주는 가장 중요한 해석은 선형변환의 기하학이다. V^⊤는 입력공간을 어떤 직교축으로 돌려 놓고 Σ는 그 축 방향으로 길이를 σi만큼 늘리거나 줄이며 는 결과를 출력공간에서 다시 돌려 놓는다. 즉 어떤 행렬이든 적절한 좌표계에서 보면 서로 직교인 축들에 대해 독립적인 스케일링으로 보인다는 뜻이다. 이 관점이 잡히면 SVD는 단순한 분해가 아니라 변환의 본질을 읽는 언어가 된다.
singular value는 고유값과도 깊게 연결된다. A⊤A는 n×n 대칭 양의 준정부호 행렬이고 AA⊤는 m×m 대칭 양의 준정부호 행렬이다. 이 둘의 고유값은 0 이상이며 그 고유값의 제곱근이 singular value가 된다.
SVD는 랭크와도 바로 이어진다. Σ에서 0이 아닌 singular value의 개수가 rank(A)다. 이때 U의 앞쪽 열벡터들은 의 column space를 이루고 의 앞쪽 열벡터들은 row space를 이룬다. 그리고 나머지 열벡터들은 각각 left null space와 null space를 채운다. 즉 SVD 하나로 네 가지 기본 부분공간의 구조가 한 번에 정리된다.
Singular Value Decomposition과 Eigendecomposition
Singular Value Decomposition은 SVD라고 부르고 eigenvector decomposittion은 보통 eigendecomposition이라고 부른다. 둘 다 행렬을 더 이해하기 쉬운 형태로 바꾸는 방법이다. 하지만 무엇을 기준으로 축을 잡는지가 다르다.
eigendecomposition은 정사각 행렬에서 의미가 또렷하다. 어떤 eigenvector는 행렬을 한 번 적용해도 방향이 유지되고 크기만 eigenvalue만큼 바뀐다. 그래서 이 분해는 변환이 스스로 유지하는 고정 축을 찾는 관점이다. 다만 모든 정사각 행렬이 깔끔하게 diagonalization되는 것은 아니다. eigenvector가 충분하지 않으면 원하는 형태로 분해가 성립하지 않거나 수치적으로 불안정해지기 쉽다. 그리고 eigenvalue는 실수가 아니라 복소수가 될 수도 있다.
SVD는 더 넓은 범위를 커버한다. 직사각 행렬도 되고 거의 모든 실수 행렬에서 항상 정의된다. 형태는 A equals U Σ V^T로 쓴다. 여기서 V는 입력 공간의 orthogonal basis이고 U는 출력 공간의 orthogonal basis이다. Σ는 각 축이 얼마나 늘어나고 줄어드는지를 singular value로 담는다. 즉 입력을 한 번 회전시키고 축 방향으로 늘리거나 줄이고 다시 회전시키는 그림으로 변환을 해석하는 방식이다.
두 분해의 핵심 차이는 축의 조건이다. eigendecomposition은 변환 전과 변환 후가 같은 방향인 축을 요구한다. SVD는 그런 조건을 요구하지 않는다. 대신 길이 변화가 가장 큰 입력 방향과 그에 대응하는 출력 방향을 짝으로 잡는다. 그래서 SVD는 방향 보존보다 크기 변화와 에너지 전달을 기준으로 중요한 축을 정렬한다.

둘은 A^T A를 통해 연결된다. right singular vector는 A^T A의 eigenvector이고 singular value의 제곱은 A^T A의 eigenvalue이다. left singular vector는 A A^T의 eigenvector로 대응된다. 이 관계 때문에 SVD는 원래 행렬을 직접 고정 축으로 해석하기보다 길이 변화가 잘 드러나는 형태로 재표현한 것이라고 볼 수 있다.
symmetric matrix에서는 두 이야기가 거의 합쳐진다. symmetric이면 orthogonal eigenvector basis가 잘 서고 SVD의 U와 V가 같은 방향으로 맞춰진다. 또한 singular value는 eigenvalue의 absolute value로 해석된다. positive semidefinite이면 eigenvalue가 음수가 없으니 두 값이 사실상 일치한다.
통찰은 non normal matrix에서 선명해진다. 어떤 변환은 eigenvalue만 보면 늘림이 없는 것처럼 보이는데 실제로는 shear 같은 왜곡으로 길이가 크게 변할 수 있다. 이때 eigendecomposition은 고정 축 관점이라 왜곡의 강도를 놓치기 쉽다. SVD는 unit circle이 ellipse로 바뀌는 정도를 singular value로 바로 보여준다. 그래서 안정성과 근사 관점에서는 SVD가 더 직접적이다.
정리하면 eigendecomposition은 모드 해석과 dynamics 해석에 강한 도구이다. SVD는 항상 존재하고 orthogonality를 기반으로 해서 수치적으로 안정적이며 least squares와 pseudoinverse와 low rank approximation 같은 문제에 강하다. 목적이 고정 축과 고유한 모드를 보는 것인지 아니면 변환이 길이를 어떻게 바꾸는지와 어떤 방향이 중요한지를 보는 것인지에 따라 선택이 갈린다.
Real Number Matrix
실수 행렬은 모든 원소가 실수 real number인 행렬이다. 즉 각 entry가 1, -3.2, √2 같은 실수로만 이루어진 행렬이다. 반대로 원소 중 하나라도 복소수 complex number가 섞이면 복소 행렬 complex matrix이다. 원소가 정수 integer면 정수 행렬이고 원소가 유리수 rational number면 유리 행렬이라고 부르지만 보통은 실수 행렬과 복소 행렬 구분이 가장 자주 쓰인다.
실수 행렬이 아닌 대표적인 경우는 복소 행렬이다. 복소수는 a + bi 형태이고 i는 i^2 = -1을 만족한다. 원소가 이런 형태이면 복소 행렬이다. 복소 행렬이 자연스럽게 등장하는 상황은 signal processing과 wave, quantum mechanics 같은 분야이다.
예를 들어 Fourier transform을 쓰면 실수 신호도 주파수 영역에서 복소수 계수로 나타난다. 그래서 FFT 결과를 행렬로 모으면 복소 행렬이 된다. 또한 회전과 진동을 위상 phase까지 포함해 표현할 때도 복소 표현이 편리해서 복소 행렬이 자주 나온다.
실수 행렬인데도 eigenvalue가 복소수가 되는 경우가 있다. 이 점이 혼동 포인트이다. 행렬의 원소는 실수인데 고유값은 복소가 될 수 있다. 예를 들어 2차원 회전 행렬은 원소가 전부 실수지만 고유값은 e^{±iθ} 형태의 복소수이다. 이때 행렬이 실수 행렬이라는 사실은 바뀌지 않는다. 다만 eigendecomposition을 복소수 공간에서 다루어야 한다는 뜻이다. 반대로 SVD는 실수 행렬에 대해 U, Σ, V를 실수로 잡을 수 있고 singular value는 항상 실수이며 0 이상이다.
PCA
PCA는 Principal Component Analysis의 약자이다. 데이터가 여러 차원에 흩어져 있을 때 분산 variance가 큰 방향을 찾아서 그 방향으로 좌표계를 다시 잡는 방법이다. 목적은 차원 축소 dimensionality reduction과 구조 파악이다.
데이터를 행렬 X로 둔다. 보통 샘플이 N개이고 feature가 d개이면 X는 N×d이다.
PCA는 먼저 각 feature의 평균을 빼서 mean-centering을 한다. 그다음 공분산 행렬 covariance matrix C를 만든다. C는 (1/(N-1)) X^T X 형태이고 d×d 대칭 행렬이다. PCA는 이 C의 eigendecomposition을 해서 eigenvector를 찾는다. 분산이 큰 방향일수록 eigenvalue가 크고 그에 대응하는 eigenvector가 principal component이다.
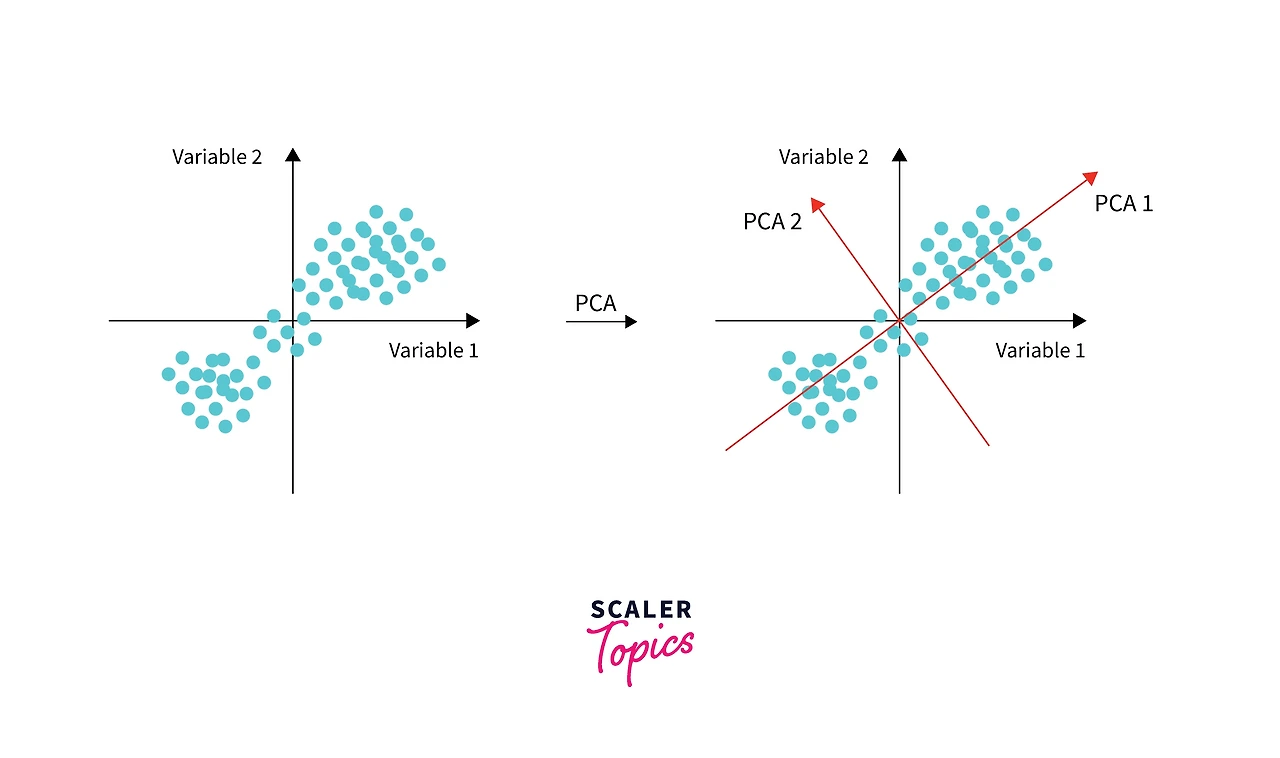
principal component의 해석은 간단하다. 첫 번째 principal component는 데이터가 가장 길게 퍼진 방향이다. 두 번째 principal component는 첫 번째와 orthogonal하면서 그다음으로 퍼진 방향이다. 이렇게 k개만 고르면 d차원을 k차원으로 줄이면서도 데이터의 분산을 최대한 보존한다. 계산은 보통 SVD로 많이 한다. centered data 행렬 X에 대해 X = U Σ V^T를 구하면 V의 열벡터가 principal component 방향이 된다. 그리고 Σ의 제곱을 (N-1)로 나누면 공분산의 eigenvalue에 해당하는 분산 크기가 된다. 이 방식은 d가 크거나 수치 안정성이 중요할 때 유리하다. PCA가 잘 쓰이는 상황은 데이터에 redundancy가 많고 몇 개의 핵심 축이 구조를 설명할 때이다. 예를 들어 고차원 임베딩을 2D로 내려서 시각화하거나 noise를 줄이거나 회귀나 분류 전에 feature를 압축할 때 쓴다. 주의점도 있다. PCA는 선형 방법이라 nonlinear 구조는 잘 못 잡는다. 또 분산이 크다는 것이 과제에서 중요한 정보라는 보장은 없다. 스케일이 큰 feature가 방향을 지배할 수 있어서 표준화 standardization이 필요한 경우가 많다. 한 줄로 요약하면 PCA는 데이터의 “가장 중요한 직교 축”을 찾아서 그 축으로 데이터를 재표현하는 방법이다.
variance & covariance
variance와 covariance가 중요한가라는 질문은 결국 데이터에서 무엇을 보존하고 무엇을 버릴지의 기준을 분산으로 잡아도 되는가라는 질문이다. 결론부터 말하면 중요한 경우가 많지만 항상 옳은 기준은 아니다. 분산이 크다는 사실은 데이터가 그 방향으로 많이 변한다는 뜻이지 그 변동이 과제에 유용하다는 뜻은 아니다.

중요한 경우부터 정리한다. 첫째, signal이 분산을 통해 나타나는 문제에서 분산은 직접적인 정보량의 대용물이 된다. 예를 들어 센서 데이터에서 특정 축의 변화가 실제 물리량 변화에 대응하고 noise는 상대적으로 작다면 큰 분산을 가진 축이 핵심이다. 둘째, least squares나 Gaussian 가정이 강한 모델에서는 covariance 구조가 곧 최적화와 일반화에 영향을 준다. 선형회귀에서 X의 covariance는 condition number와 추정 분산을 좌우하고 이는 학습 안정성과 예측 오차로 바로 이어진다. 셋째, 거리 기반 방법에서는 covariance가 metric을 정의한다. Mahalanobis distance는 covariance를 반영해 스케일과 상관을 제거한 거리이며 anomaly detection에서 특히 유효하다. 넷째, 차원 축소 목적이 “재구성 오차 reconstruction error 최소화”라면 PCA가 최적이고 그 최적성은 분산 보존과 동치이다. 즉 데이터를 압축해서 다시 복원하는 목적이면 분산은 매우 중요한 기준이다.
반대로 안 중요한 경우도 분명하다. 첫째, label이 있는 supervised task에서 분산이 큰 방향이 label과 무관하면 그 방향은 방해가 된다. 예를 들어 사람 키와 몸무게로 성별을 분류하는데 키의 분산은 매우 크지만 성별 구분에는 특정 비율이나 다른 feature가 더 중요할 수 있다. 더 극단적으로는 조명 변화처럼 분산이 큰 nuisance factor가 존재하면 PCA는 그 nuisance를 가장 먼저 잡는다. 둘째, class separation이 작은 분산 방향에서 발생할 수 있다. 두 클래스가 거의 같은 구름인데 아주 얇은 방향으로만 살짝 분리되는 경우가 있다. 이때 분산이 작은 축이 오히려 결정 경계에 중요하다. PCA로 큰 분산만 남기면 분류 성능이 떨어질 수 있다. 셋째, 데이터가 non linear manifold 위에 있으면 covariance는 전역적인 2차 통계로는 구조를 제대로 표현하지 못한다. 예를 들어 원형으로 말린 데이터는 분산이 크지만 실제 자유도는 1차원에 가깝다. 이때는 kernel PCA, Isomap, UMAP 같은 방법이 더 적합하다. 넷째, heavy tail이나 outlier가 많으면 분산과 covariance가 안정적인 통계량이 아니다. 몇 개의 outlier가 covariance를 지배하고 중요한 패턴을 가릴 수 있다. 이 경우 robust covariance, median 기반 방법, trimming이 필요하다. 다섯째, feature scaling이 맞지 않으면 분산은 단위에 의해 결정된다. 섭씨와 밀리미터를 섞어 놓으면 큰 숫자 단위가 principal component를 지배한다. 이때 분산 자체는 의미가 아니라 전처리의 실패를 반영한다.
그래서 분산과 covariance를 “중요하게 써도 되는 조건”은 대략 다음처럼 정리된다. 목적이 재구성이나 압축이고 데이터의 변동이 곧 signal이며 noise가 작은 편이고 스케일이 정리돼 있으며 대체로 선형 구조를 기대할 때이다. 반대로 “조심해야 하는 조건”은 label이 있고 nuisance가 큰 문제이거나 class separation이 미세한 축에서 일어나거나 구조가 비선형이거나 outlier가 많거나 단위가 뒤섞인 경우이다.
'대학수업' 카테고리의 다른 글
| 디지털시스템입문-2 (2) | 2025.09.16 |
|---|---|
| 디지털시스템입문-1 (0) | 2025.09.09 |
| [확률과 통계] 기술 통계 (0) | 2022.11.19 |
| [시스템 프로그래밍] Exceptional Control Flow (0) | 2022.11.13 |
| [JavaScript] 연산자 (0) | 2022.11.04 |



