
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- streamlit
- REST API
- 1101
- 파이싼
- 티스토리챌린지
- 9020
- 그리디 알고리즘
- 4948
- 신경망 학습
- video retireval
- 백준
- Retrieval
- 손실함수
- 1002
- n과 m
- BOJ
- 15649
- 가상환경
- 밑바닥부터 시작하는 딥러닝
- 백트래킹
- 오블완
- Python
- 재귀
- end to end
- 파이썬
- 기계학습
- 경사하강법
- N-Queen
- pyenv
- 개발환경
- Today
- Total
파이톨치
[밑바닥부터 시작하는 딥러닝] 신경망 학습 본문
포기하지 말시길...
제 생각에는 이번 장부터는 내용이 어려워지고 분량도 많이집니다. 관련된 지식을 이미 알고있는 사람이라면 어렵지 않게 이해하겠지만 처음배우는 입장에서는 이번 장부터 난이도가 급격하게 올라갈 수 있습니다. 저 또한 이번 장부터는 잘 설명할 수 있을지 모르겠습니다. 이번 장에서 배우는 내용은 "학습" 이라는 것입니다. 앞에서도 말했다 싶이 학습이라는 것은 데이터의 패턴을 익히는 과정입니다. 우리가 이번에 할 내용은 어떻게 신경망은 데이터의 패턴을 익히는가 입니다.
학습을 하지 않는다면, 처음에 우리가 퍼셉트론을 만들 때 했던 것처럼 가중치를 하나하나 상황에 맞게 바꾸어 주어야 합니다. 하지만 이렇게 하는 경우에 데이터가 수백만개가 된다면, 우리는 평생을 가중치만 수정하다가 인생이 끝날지도 모릅니다. 때문에 가중치를 자동으로 바꾸어 주는 작업을 하는데 이것을 학습이라고 합니다. 책에는 다음과 같이 정의되어 있습니다.
학습이란 훈련 데이터로부터 가중치 매개변수의 최적값을 자동으로 획득하는 것
호기심이 많은 분들은 이런 궁금증이 생길 수 있습니다. "그러면 가중치는 어떻게 자동으로 수정하는거지?" 하는 생각입니다. 우리는 가중치를 평가해서 이를 수정하는 과정을 거칩니다. 우리가 정답 데이터를 가지고 있을 때, 정답과 예측한 값을 비교하면서 얼마나 틀렸는지를 기준으로 학습을 진행합니다. 고등학생 때 모의고사를 보면서 틀린 개수가 몇개인지를 체크하면서 학습을 한 경험이 있을 것입니다. 그것과 비슷한 맥락입니다. 맞은 문제에 집중하기 보다는 얼마나 틀렸는지를 보는 것입니다. 이러한 것을 체크해주는 함수를 우리는 손실함수라고 부릅니다.
데이터 주도 학습
우리가 이러한 학습을 왜 배워야 하는지 설득을 해보겠습니다. 딥러닝은 결국 데이터 과학이라고 생각합니다. 기존의 알고리즘들은 사람의 머리에서 나온 것들이었습니다. 똑똑한 선배님들이 잘 정리해서 우리가 사용하는 것들이겠죠. 혹은 상황에 맞게 설계할 것입니다. 하지만 이러한 경우 저는 멍청하기 때문에 상황에 맞는 알고리즘을 잘 설계할 자신이 없습니다. 예를 들어서 다음 그림을 한번 봅시다.

위와 같은 데이터가 주어졌을 때, 손글씨를 넣었을 때 5를 인식하는 알고리즘을 만들어야 합니다. 알고리즘을 우리가 만드는 경우에는, 5라는 것은 c를 뒤집은 모양과 2개의 직선이 ㄱ을 뒤집은 모양을 합친 것이다. 조금 자세하게 써보자면, 한개의 선분이 있을 때 이와 거의 수직인 선분 하나가 연결 되어 있기 여기에 x ** 2의 함수 꼴을 90도 회전시킨 모양이 결합된 것이다. 대충 이런 식으로 만들 수 있는데 실제로 구현하려고 하면 더욱 더 복잡해질 것입니다. 또한 대충 쓴 손글씨도 많기에 이를 모두 만족시키는 알고리즘을 만들기란 쉽지 않겠죠.
하지만 딥러닝을 통해 우리가 학습이라는 과정을 하면, 알고리즘을 만들 필요가 없습니다. 그저 데이터를 넣어주고 알아서 패턴을 찾으라고 시키니까 말이죠. 그 차이를 그림으로 보면 다음과 같습니다.

이런 식으로 딥러닝은 사람의 개입이 더 적게 들어갑니다. 우리는 이러한 것을 end-to-end 라고 부릅니다. 처음부터 끝까지라는 의미로 사람의 개입이 필요없다는 것이죠.
손실함수
앞에서 언급한 손실함수를 설명해보겠습니다. 손실함수는 현재의 상태를 하나의 지표로 표현한 것입니다. 모의고사를 풀 때, 최고점을 받기 위해 틀린 문제를 공부하듯이 우리는 최적의 매개변수 값을 찾기 위해 손실함수를 따라 매개변수를 조정합니다. 손실함수는 다양한 형태로 존재하며, 상황에 맞는 손실함수를 사용하면 됩니다.
이를 배우기 전에 우리는 원-핫 인코딩에 대해 잠시 살펴보아야 합니다. 원-핫 인코딩을 모르면, 뒤에 나오는 내용을 조금은 이해하기 힘들 수도 있습니다. 원-핫 인코딩은 0~9까지 있는 손글씨가 있을 때 5라는 숫자를 표현하기 위해서 길이가 10인 배열을 만들어 5에 해당하는 인덱스의 값을 1로 설정하고 나머지는 0으로 설정하는 것입니다. 예를 들어서 [0, 0, 0, 0, 0, 1, 0, 0, 0, 0] 와 같은 형태가 될 것입니다.
가장 직관적으로 이해하기 쉬운 함수는 "오차제곱합"입니다. 정답과 얼마나 다른지를 체크하여 이를 제곱한 후에 2로 나누어 주면 됩니다.

수식이라 복잡해 보일 수 있지만, 조금 관찰해보면 어떤 의미인지 쉽게 알 수 있습니다. 파이썬으로 이를 구현하면 다음과 같습니다.
def sum_sqares_error(y, t):
return 0.5 * np.sum((y-t)**2)여기서 주목해야하는 점은 t로 들어가는 입력이 원-핫 인코딩된 값이라는 점입니다. y와 t는 다음과 같이 설정할 수 있습니다. y의 값은 각각의 인덱스에 대한 확률을 나타낸 것입니다. 0.1은 0일 확률이고, 0.6은 2일 확률 입니다. 정답이 2이고 2일 확률이 가장 높게 나왔기 때문에 올바르게 예측했다고 할 수 있습니다.
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0])
t = np.array([0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
print(sum_squeres_error(y, t)) # 결과 : 0.09750000000000003이 경우에 올바르게 예측을 했기 때문에 오차함수의 값이 작게 나온 것입니다. 잘못된 예측을 하게 된다면 이보다 큰 값이 나오고 더 정확한 예측을 한다면 이보다 작은 값이 나올 것입니다.
또 다른 손실 함수는 교차 엔트로피 오차 혹은 크로스 엔트로피 오차라고 부릅니다. 이름에 엔트로피가 들어가서 어디가서 유식한 척하기 좋은 이름의 함수입니다.
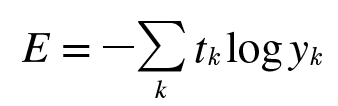
log가 나오니까 식이 보기 싫어지지만, 그렇게 복잡한 함수는 아닙니다. 위의 예시를 생각해보면 t는 [0, 0, 0, 0, 0, 1, 0, 0, 0, 0] 과 같은 형태로 되어 있었습니다. 때문에 이 식은 t가 1인 값을 뽑아서 생각하는 것입니다. 0은 알 것 없다는 얘기입니다. t가 1이라면 이제는 log x의 그래프를 따라서 가는 것입니다. log x는 다음과 같이 생겼습니다.
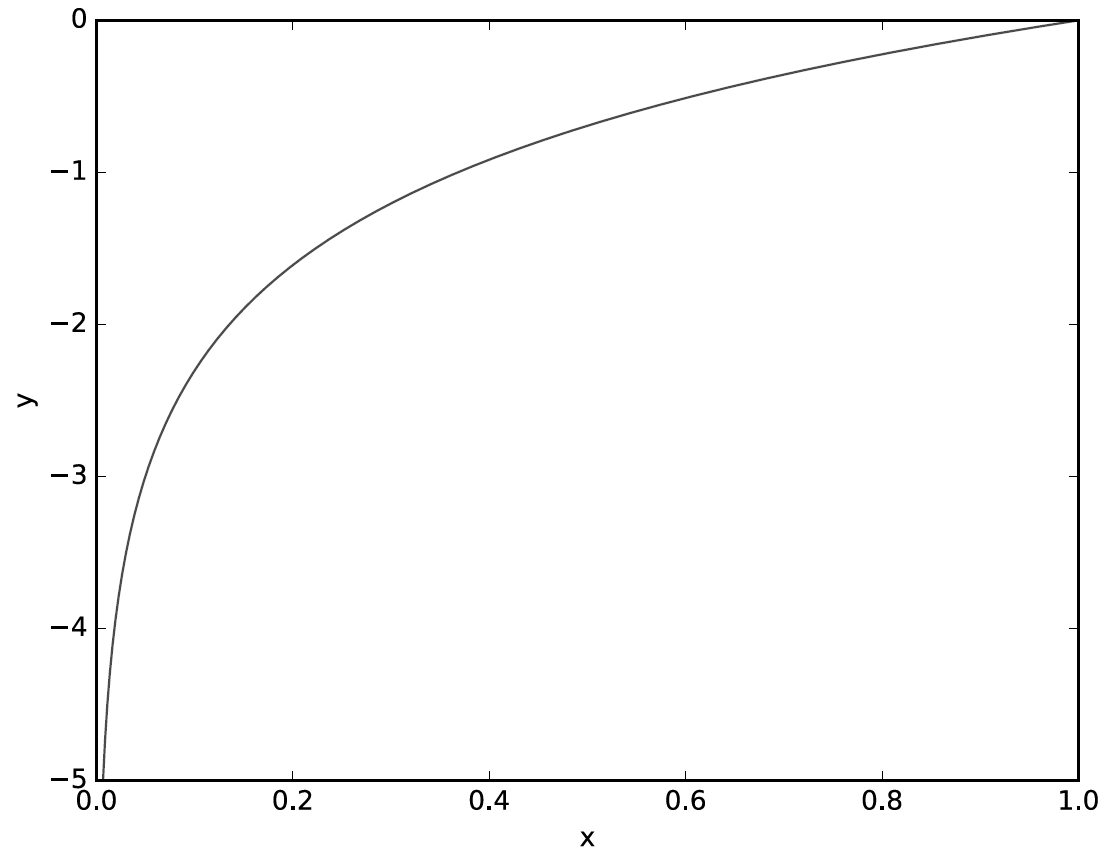
때문에 크로스 엔트로피 오차는 정답에 가깝게 예측할 수록 0에 가까운 값을 정답에 멀수록 무한대에 가까운 값이 나온 것입니다.
log x의 그래프와 수식을 보면서 수식에 - 가 왜 붙었는지는 스스로 생각해보세요 😋
하지만 이 무한대라는 값은 처리하기 곤란하기 때문에 아주 작은 값을 더해서 무한대가 생기지 않게 만들어줍니다.
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
print(cross_entropy_error(y, t)) # 결과 : 0.510825457099338y와 t는 위와 동일한 값입니다. 위의 오차제곱합과 더 큰 값이 나오긴 했지만 함수마다 스케일의 차이가 있는 것입니다. 데이터를 조정해보면 알겠지만, 결과적으로 둘이 동일한 판단을 하고 있습니다.
어떤 사람은 "정답을 높이는 것이 아니라 손실을 줄이는 방향으로 만드는가?"하는 의문을 가질 수 있습니다. 결국 우리가 하는 것은 정확도를 높이려고 하는 것인데 왜 손실함수를 만들었을까요? 그것은 학습을 하는 원리에 미분이 있기 때문입니다. 우리는 손실함수를 미분해서 이 미분값이 가장 작아지는 지점을 최적의 매개변수 값으로 생각하기 때문에 손실함수를 만들어 최소점을 찾는 것입니다. 추측을 해보자면 점점 커지는 값을 다루는 것보다 0 근처에서 최적의 값을 다루는 것이 오버플로우도 나지 않을 것입니다. 여러가지 이유가 있겠지만, 처음 배우는 우리 입장에서는 그렇게 딥러닝이 발전해왔다 정도로 생각하면 편할 것입니다. 참고로, 정확도를 지표로 삼지 않는 이유는 함수가 불연속적인 값이 나와 미분하는 의미가 없기 때문입니다.
수치미분
수치 미분은 원리를 이해하기 좋지만, 사용하지는 않습니다. 왜냐하면 너무나 느리기 때문입니다. 제 추측이지만, 수치미분은 지금만 배우고 앞으로는 쓸 일은 없을 것입니다. 하지만 그럼에도 불구하고 기본원리이니 배워보자면, 수치미분은 아주 작은 차분으로 미분하는 것이라고 합니다. 정확한 미분이 아니라 조금의 오차가 있는 미분입니다. 실제 미분과의 차이를 보여주는 그림입니다.
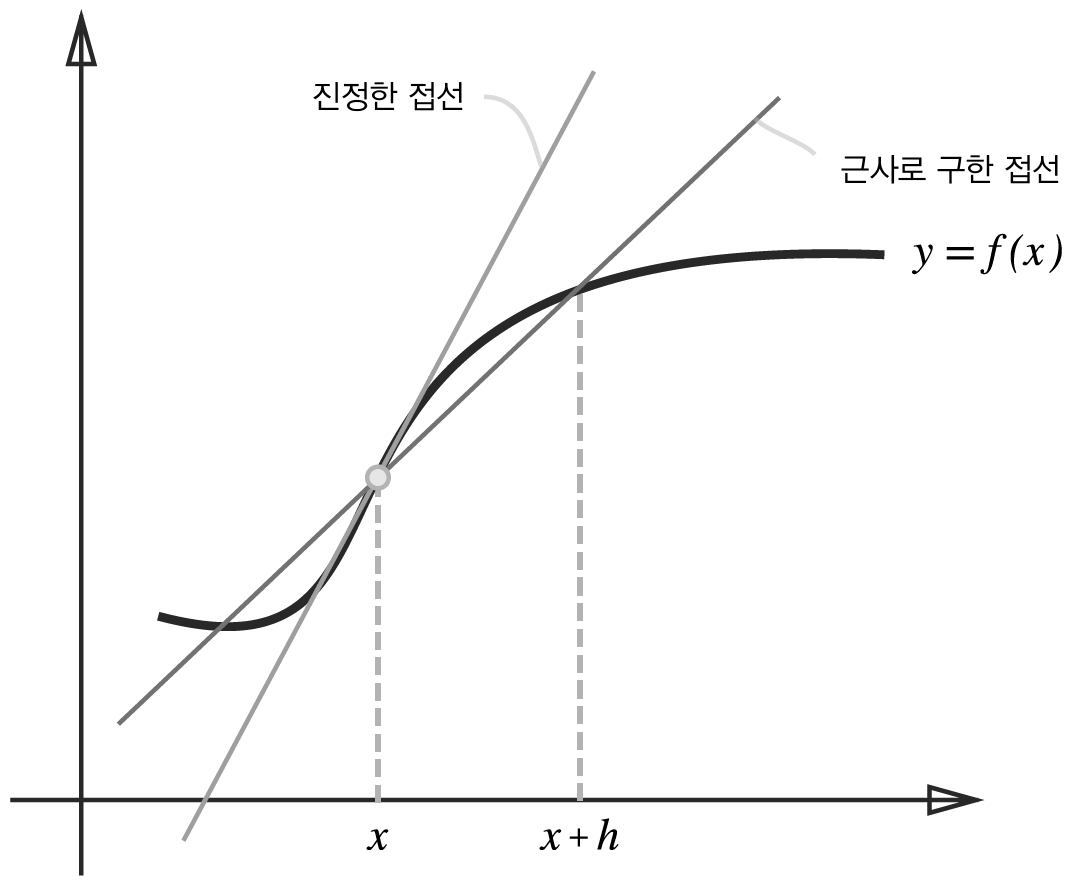
이를 코드로 구현하면 다음과 같습니다. 이는 위의 그림을 그대로 작성한 것은 아니고 중앙 차분을 한 것입니다.
def numerical_diff(f, x):
h = 1e-4 # 10 ** -4
fxh1 = f(x+h)
fxh2 = f(x-h)
grad = (fxh1 - fxh2) / (2*h)
return grad아주 작은 값의 차이 만큼 더하고 빼서 그 중심의 미분값을 구하는 것입니다. 실제로 돌려보면 실제 미분결과와 큰 차이는 없습니다.
여기서 차원을 늘려봅시다. 편미분의 개념을 생각해서 각각의 변수별로 미분을 하고 이를 저장하는 방식입니다.
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x) # 반환해줄 기울기
for idx in range(x.size):
tmp_val = x[idx] # 해당 차원의 값
x[idx] = tmp_val + h
fxh1 = f(x)
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 계산 후, 복원
return grad참고로 차원이 달라진 만큼 위의 두 코드는 들어가는 f가 다릅니다. 아래 함수는 f = x0 ** 2 + x1 ** 2의 형태입니다.
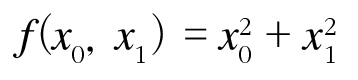
그래프의 기울기를 화살표를 넣어서 보면 다음과 같습니다.
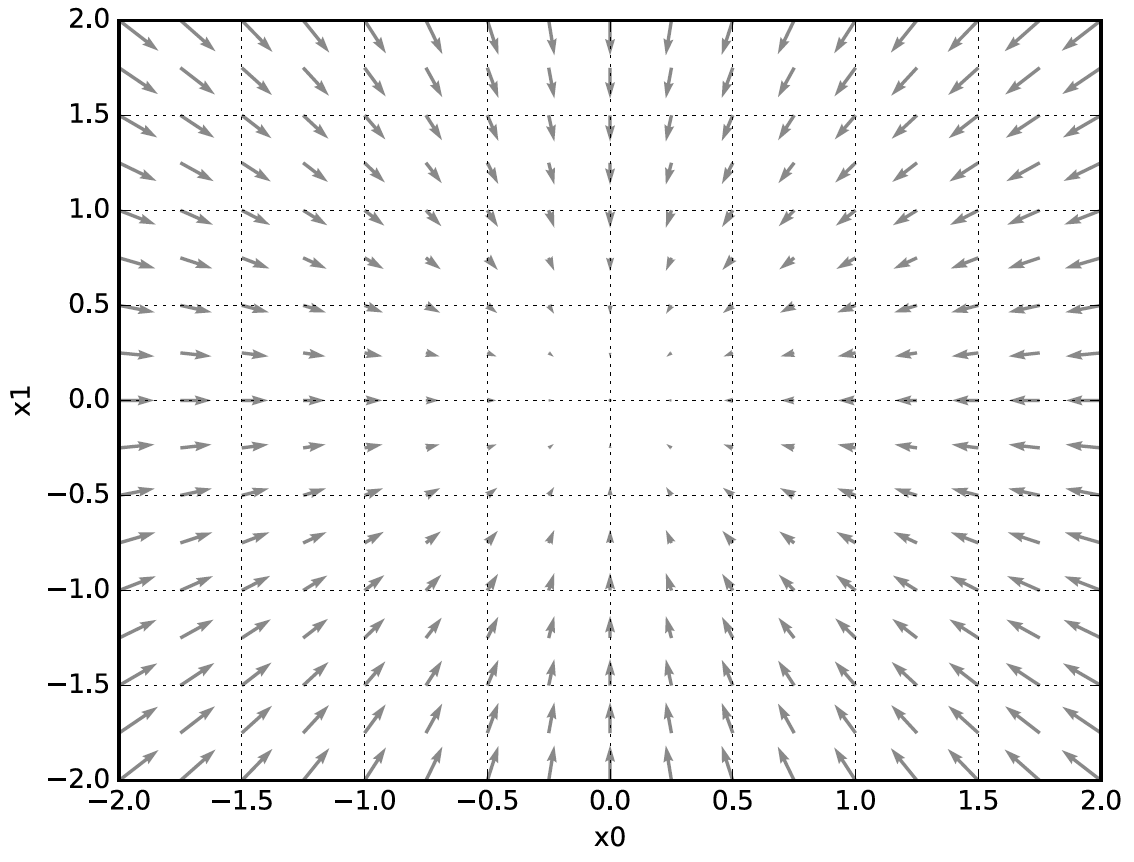
자세히 살펴보면, 특정한 한 점으로 모이는 것을 볼 수 있습니다. 우리가 찾고자 하는 매개변수의 최적은 저런 식으로 화살표가 가리키는 방향입니다. 화살표의 방향과 크기는 사실 기울기의 방향과 크기라는 것을 알 수 있습니다.
기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향입니다.
이 원리를 이용해서 나온 것이 경사 하강법입니다. 기울기 따라서 쭉 간다고 해서 경사 하강법입니다. 산에서 내려갈 때 경사를 따라서 내려가 잖아요 그것과 비슷합니다만 수식을 보면 무서울 수 있습니다. 하지만 우리는 코딩쟁이들이니까 코드를 보면 이해가 잘 될 것입니다. 수식은 다음과 같습니다.
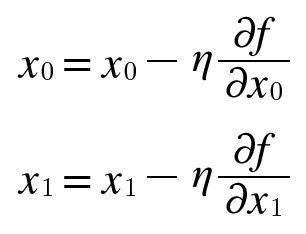
뭔가 알 수 없는 기호가 보이는데 저기서 n 비슷하게 생긴 저 문자는 학습률이라고 하는 것입니다. 기울기를 얼마나 따라갈지를 정해주는 역할로 산을 타고 내려갈 때 보폭을 얼마나 할지를 정해주는 것입니다. 산을 내려갈 때 보폭이 너무 크면 넘어지고 보폭이 너무 작으면 내려가는데 시간이 너무 오래 걸리니까 적당한 보폭으로 내려가 주는 것이 가장 좋습니다.
이를 코드로 보면 다음과 같습니다.
def gradient_descent(f, init_x, lr=0.01, step_sum=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x이런 식으로 x값을 최소화 하는 방향으로 x값을 수정해줍니다. 변화 추이를 보면 다음과 같습니다.
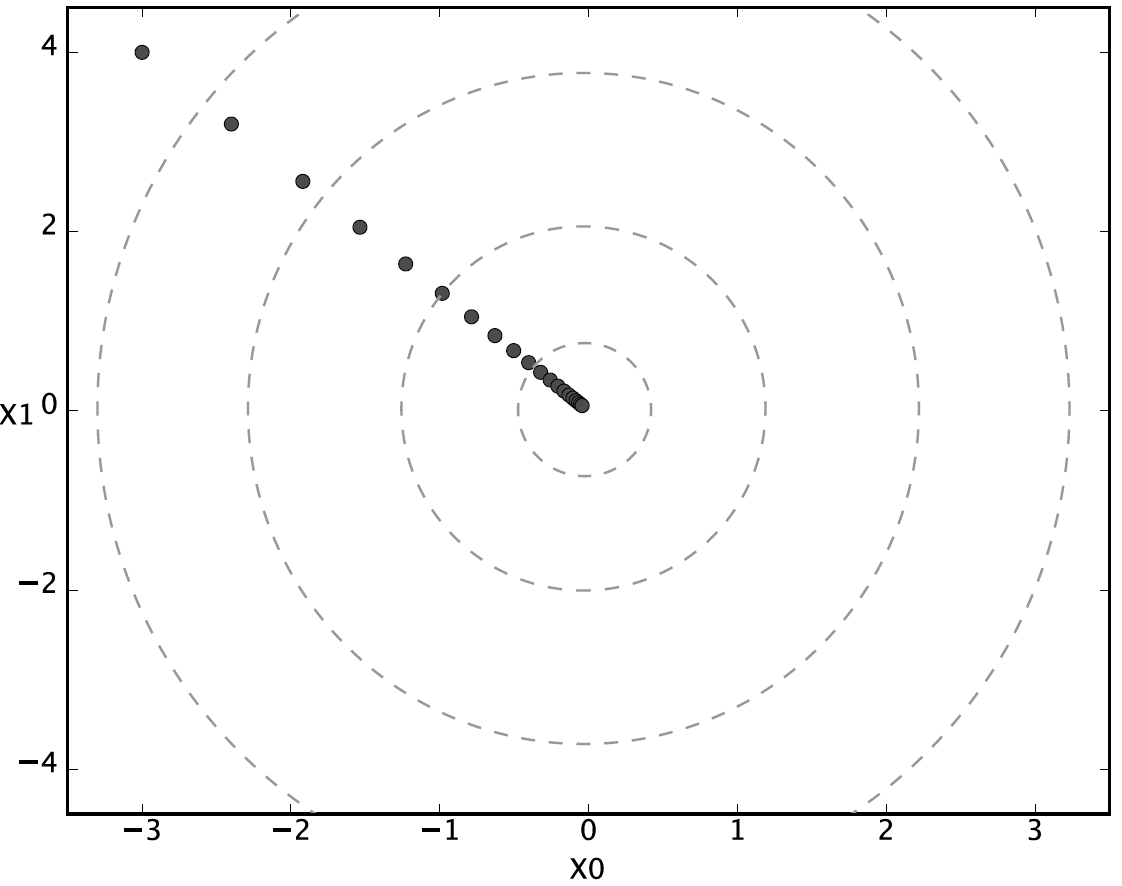
이런 식으로 오차함수와 수치미분을 하면 최적의 매개변수를 찾아낼 수 있습니다. 하지만 앞에도 말했다 싶이 이는 너무나 느린 방법입니다. 데이터가 많아졌을 때, 매번 미분 값을 계산을 하는 것은 컴퓨터 입장에서 부담스러운 일입니다. 아마 수치미분을 해서 신경망을 학습해야 했다면 오늘날의 인공지능을 없었을지도 모른다는 생각이 듭니다. 하지만 이를 멋지게 해결한 방법이 있고, 그 이름은 오차 역전파법입니다. 데이터가 커지면 둘의 학습에 소요되는 시간의 차이는 커집니다. 이는 뒤에서 다룰 예정입니다. 하지만 기본적인 아이디어는 위와 같은 아이디어이며 고등학생 때 배운 미분을 통해 설명할 수 있어서 이해하기 편합니다. 이제 이를 이해했으니 오차 역전파법을 배울 차례입니다.
'AI&ML > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝] 오차역전파법 학습 코드 (0) | 2023.01.03 |
|---|---|
| [밑바닥부터 시작하는 딥러닝] 오차역전파법 (0) | 2022.12.31 |
| [밑바닥부터 시작하는 딥러닝] 신경망 구현하기 (0) | 2022.12.27 |
| [밑바닥부터 시작하는 딥러닝] 신경망 (0) | 2022.12.26 |
| [밑바닥부터 시작하는 딥러닝] 퍼셉트론 (4) | 2022.12.26 |



