
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
Tags
- Python
- 그리디 알고리즘
- 신경망 학습
- pyenv
- 경사하강법
- n과 m
- 1002
- 백트래킹
- 손실함수
- 파이싼
- BOJ
- 1101
- 백준
- 15649
- Mac
- 가상환경
- streamlit
- 개발환경
- 기계학습
- 밑바닥부터 시작하는 딥러닝
- N-Queen
- 4948
- 파이썬
- 실버
- 9020
- end to end
- 재귀
- 설정
Archives
- Today
- Total
파이톨치
[Dacon] Samsung AI Challenge 2024 본문
728x90
# train 상위 10% 데이터 분석
강의에서 배운 2D 히스토 그램을 써보았음. 단순 scatter 하는 것보다 밀집도를 보기 편함.
x_8 데이터가 중요하지 않다고 생각했는데, x_8 값이 0.60보다 작을 때 밀집도가 높은 것을 볼 수 있음.
때문에 해당 데이터가 test에서 중요한 영향을 끼칠 것 같음.

그래서 x_8 데이터에서 x_8값이 0.58보다 작을 때 가중치를 부여하거나 오버샘플링하는 방식으로 학습을 해야 할 것이라는 생각이 들었음. 그러면 오버 샘플링을 해야하는게 아닐까? 하는 생각이 든다.
그래서 데이터를 더 이어 붙여주었더니, 데이터 분포가 비슷해졌다!! 아 이거다!!
# train 상위 5% 데이터 분석
5퍼센트일 때는 그 경향성이 더 두드러진다.
이때, 경계가 더욱 명확해진다.
x_3, x_8에 대해서 그 경계가 보인다.

# Test 데이터의 X값 분포

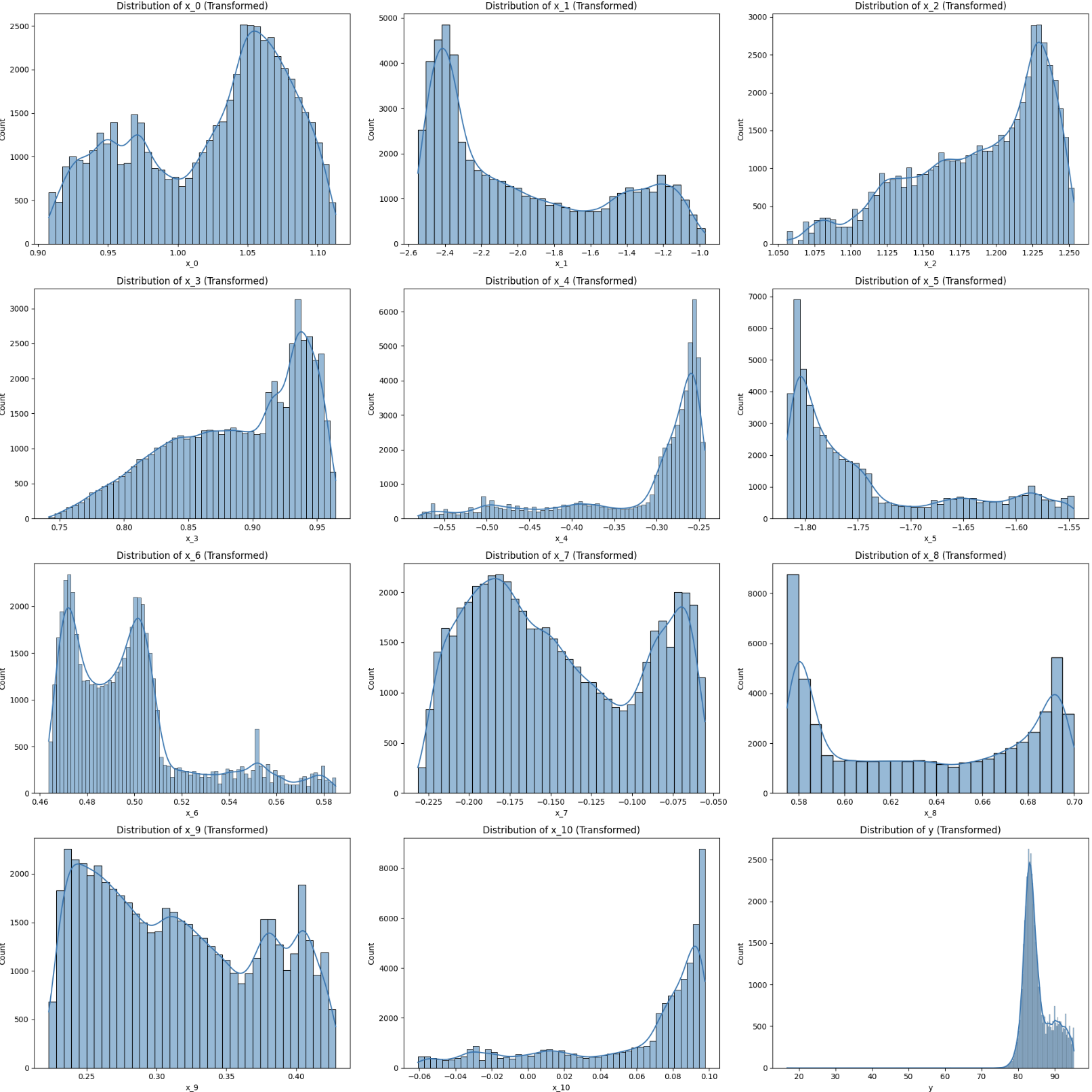
잘 보면 x_8이 0.58일 때, 값이 많은 것을 볼 수 있다.
즉, test 데이터에는 y값이 큰 값이 많은 것이라고 추론할 수 있다.
# Train 데이터의 X값 분포

test 데이터랑 차이를 보면 x_8이 0.58일 때, 값이 차이가 난다.
# Train 데이터 보강
# x_8 값이 0.59보다 작은 데이터 추출
df_small_x8 = df[df['x_8'] < 0.58]
df = pd.concat([df, df_small_x8, df_small_x8, df_small_x8, df_small_x8], ignore_index=True)
print(len(df_small_x8))
df_small_x8 = df[df['x_3'] > 0.93]
df = pd.concat([df, df_small_x8,], ignore_index=True)
print(len(df_small_x8))
df_small_x8 = df[df['x_9'] > 0.40]
df = pd.concat([df, df_small_x8, df_small_x8,], ignore_index=True)
print(len(df_small_x8))
df_small_x8 = df[df['x_9'] > 0.42]
df = pd.concat([df, df_small_x8, df_small_x8, df_small_x8], ignore_index=True)
print(len(df_small_x8))
df_small_x8 = df[df['x_6'] > 0.55]
df = pd.concat([df, df_small_x8], ignore_index=True)
print(len(df_small_x8))
위와 같이 train 데이터를 추가해주면 test 데이터와 비슷하게 맞출 수 있다.
728x90
'프로젝트' 카테고리의 다른 글
| [github] intial setting github With VSCode (수정 중) (0) | 2024.08.26 |
|---|---|
| [데이터 전처리] Mecab 을 사용하여 단어를 토큰화하기 (3) | 2022.09.03 |
| [Mecab 오류] Exception: Install MeCab in order to use it: http://konlpy.org/en/latest/install/ (0) | 2022.09.03 |
| [데이터 수집] AI 허브 이용하기 (0) | 2022.09.03 |
| [오류 해결] ImportError: Missing optional dependency 'openpyxl'. (0) | 2022.09.03 |
'프로젝트' Related Articles
more


