
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 9020
- 그리디 알고리즘
- REST
- Python
- end to end
- 재귀
- 티스토리챌린지
- 개발환경
- 1002
- 파이싼
- 4948
- 가상환경
- 신경망 학습
- N-Queen
- 밑바닥부터 시작하는 딥러닝
- REST API
- BOJ
- 실버
- n과 m
- streamlit
- 백준
- 손실함수
- 15649
- 경사하강법
- 파이썬
- 백트래킹
- pyenv
- 1101
- 오블완
- 기계학습
- Today
- Total
파이톨치
[BoostCamp AI Tech] CNN 시각화 본문
지난 글과 바로 이어지는 내용이다. 참고하도록 하자.
https://jung0228.tistory.com/205
[BoostCamp AI Tech] Computer Vison Overview
Computer Visoncv (computer vison)은 가장 수요가 높은 분야 중 하나이다. 네이버 부스트캠프에서도 인원이 가장 많다. 또 응용할 수 있는 부분이 많다. (채용 공고도 많은 거 같다.)그렇기 때문에, 여기
jung0228.tistory.com
지난 글에서는 CNN에 대해 다루었다. 이번 시간에는 신경망을 시각화하는 방법에 대해 다루려 한다.
파라미터를 분석하는 필터 시각화, 특징을 분석하는 t-SNE, GradCAM, DeepLIFT 등이 있다.
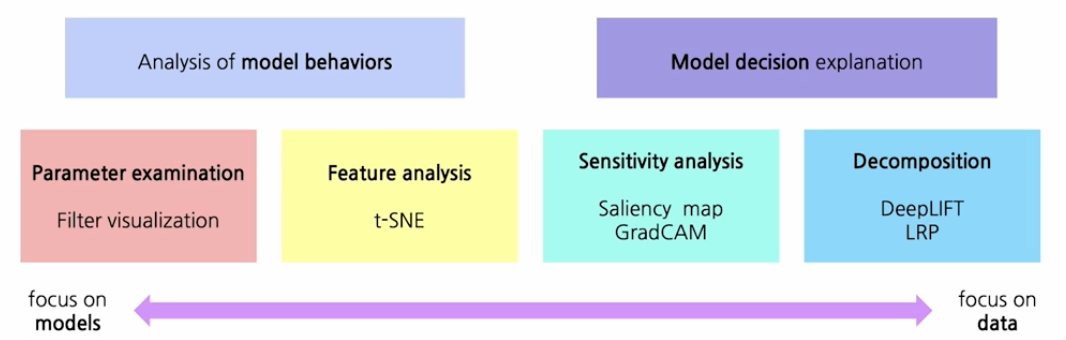
이러한 방법론은 모델에 대해 잘 이해하기 위한 것이다. 모델이 이상한 행동을 하면 이를 잘 이해하고 해결하기 위한 과학자들의 노력이라고 생각된다.
먼저, 모델의 마지막 층에 있는 벡터를 추출한다. 그 벡터는 특집 공간에 맵핑될 것이다. (이 벡터는 많은 정보를 함축하는 밀집 벡터이다.)
그런 다음 그 벡터와 유사한 벡터끼리 군집화를 한다. 그러면 어떻게 되겠는가? 유사한 벡터끼리 묶일 것이다. 그렇게 되면 유사한 이미지 끼리 묶을 수 있는 것이다. 이렇게 유사하게 묶인 이미지들을 보고 모델이 어떤 컨셉으로 이 이미지를 분류했는지 유추할 수 있다.

이러한 고차원의 벡터들(모델 마다 다르겠지만 512차원 정보의 벡터)을 직접 묶는 것은 어렵기 때문에 DB에 있는 이미지를 가져와서 분석하는 방법이다. 하지만, 차원을 축소 시키면 군집화가 쉬워진다. 저널에서 많이 쓰는 것을 본 방법이다.
t-SNE
이것을 t-SNE라고 부르는 유명한 방법이다.
MNIST라고 유명한 숫자 데이터를 아래와 같이 시각화한 것이다. 공개된 라이브러리로 사용하기 쉽다. 강의에서는 설명이 자세하지 않아 몸에 와 닿지는 않아서 ChatGPT에게 물어보았다.
(user) t-SNE에 대해 알려줘
(chatgpt) t-SNE (t-Distributed Stochastic Neighbor Embedding)는 고차원 데이터를 저차원(보통 2차원 또는 3차원)으로 시각화하는 데 사용되는 비선형 차원 축소 기법입니다. 데이터의 복잡한 패턴을 이해하거나 숨겨진 구조를 발견하기 위해 고차원 데이터를 시각적으로 탐색해야 할 때 매우 유용합니다. 주로 머신러닝에서 데이터의 군집을 시각화하거나 분류 문제에서 데이터의 분포를 이해하는 데 자주 사용됩니다.
t-SNE의 목적
t-SNE의 주요 목표는 고차원 데이터의 유사성을 보존하면서 데이터를 저차원 공간으로 변환하는 것입니다. 즉, 고차원 공간에서 가까운 데이터 포인트들은 저차원 공간에서도 가깝게 유지하고, 멀리 있는 포인트들은 멀리 떨어져 있도록 만듭니다. 이를 통해 고차원 데이터의 구조를 보다 직관적으로 이해할 수 있게 됩니다.

Gradient ascent
다음으로 소개할 방법은 Gradient ascent 방법이다. 이것은 역전파를 이용한 방법이다. 이 방법은 굉장히 재밌다. 이 방법을 통해 딥러닝 모델이 학습한 내부 특징과 패턴을 이해할 수 있으며, 모델의 투명성을 높이고, 모델이 잘못된 패턴을 학습하지 않았는지 확인하는 데 유용하다.
이 기법들은 주로 신경망의 특정 뉴런이나 출력 클래스가 어떤 패턴에 반응하는지를 시각화하기 위해 사용됩니다.
1. 사전 학습된 모델 로드
: 먼저, 사전 학습된 신경망 모델을 로드합니다. 일반적으로 이미지 분류를 위해 훈련된 모델(예: VGG, ResNet, Inception 등)을 사용합니다.
2. 특정 레이어 또는 출력 선택
: 클래스 시각화를 위해 네트워크의 특정 레이어나 출력(예: 소프트맥스 출력을 통한 클래스 확률)을 선택합니다. 예를 들어, 마지막 레이어의 출력 중 "고양이" 클래스에 해당하는 출력을 목표로 삼습니다.
3. 초기 이미지 생성
: 무작위 노이즈 이미지로 시작하거나, 특정한 초기화 이미지에서 시작합니다. 이 이미지는 클래스 시각화를 통해 점점 수정되어 나갈 것입니다.
4. 이미지 업데이트: Gradient Ascent를 사용하여 이미지를 업데이트합니다. 이미지의 픽셀 값을 기울기 방향으로 이동시켜 클래스 확률을 증가시킵니다.


쉽게 말해서 학습된 모델을 사용해서, 아무 출력을 넣는다. 그리고 역전파를 진행한다. 이 때, 역전파를 통해서 가중치를 업데이트 하는 것이 아니라 입력 이미지 자체를 업데이트 한다고 한다. 그리고 나온 이미지를 다시 넣고 반복한다. 그러면 최종적으로 모델이 생각하는 클래스에 대한 전반적인 특징이 나오게 된다. 아마 저 예측 클래스는 "새"일 것이다.
CAM (Class Activation Mapping)
Class Activation Mapping (CAM)은 딥러닝 모델, 특히 이미지 분류 신경망에서 특정 클래스가 활성화되는 입력 이미지의 영역을 시각화하는 방법입니다. CAM은 신경망이 이미지의 어떤 부분에 주목하여 특정 클래스를 예측했는지를 시각적으로 이해하는 데 도움이 됩니다. CAM을 사용하면 모델이 학습한 "시각적 증거"를 통해 모델의 예측이 어떻게 이루어지는지 알 수 있습니다.

Class Activation Mapping (CAM)의 기본 개념
CAM의 주요 아이디어는 특정 클래스의 예측 점수에 기여하는 이미지의 픽셀 위치를 강조하여 시각화하는 것입니다. 예를 들어, 모델이 "고양이" 이미지를 예측할 때, CAM은 이미지에서 모델이 "고양이"라고 예측한 이유가 되는 중요한 영역들을 하이라이트합니다.
CAM은 주로 전통적인 컨볼루션 신경망(CNN) 구조에서 적용되며, 이 과정에서 전역 평균 풀링(Global Average Pooling, GAP) 레이어와 최종 완전 연결층(fully connected layer)이 사용됩니다.
CAM의 작동 원리
CAM의 기본 아이디어는 다음과 같은 단계로 설명할 수 있습니다:
특징 맵 추출: CNN의 마지막 컨볼루션 레이어는 입력 이미지의 특징을 추출한 **특징 맵(feature map)**을 생성합니다. 이 특징 맵은 여러 개의 필터로 구성되어 있으며, 각 필터는 이미지의 다른 부분을 강조하거나 억제합니다.
Global Average Pooling (GAP) 레이어: 마지막 컨볼루션 레이어에서 나온 특징 맵은 Global Average Pooling (GAP) 레이어를 통해 처리됩니다. GAP 레이어는 각 특징 맵의 공간적 차원을 평균 내어, 하나의 숫자로 압축합니다. 즉, 각 특징 맵의 평균 값을 계산하여 벡터를 생성합니다. GAP 레이어는 다음과 같은 이유로 사용됩니다:
- 과적합 방지: GAP는 파라미터 수를 줄여 모델이 더 단순해지게 하여, 과적합(overfitting)을 방지하는 데 도움을 줍니다.
- 특징 선택: GAP는 각 특징 맵에서 중요한 정보를 요약하여 모델이 더 중요한 특징에 집중하도록 합니다.Global Average Pooling (GAP) 레이어: 마지막 컨볼루션 레이어에서 나온 특징 맵은 Global Average Pooling (GAP) 레이어를 통해 처리됩니다. GAP 레이어는 각 특징 맵의 공간적 차원을 평균 내어, 하나의 숫자로 압축합니다. 즉, 각 특징 맵의 평균 값을 계산하여 벡터를 생성합니다. GAP 레이어는 다음과 같은 이유로 사용됩니다:
아래에 있는 수식은 여전히 이해가 안 된다. CNN에 나온 값을 GAP를 해서 w를 곱하는 것까진 알겠는데, 이게 어떻게 시각화를 한다는건지 모르겠다. (아 대충 알겠다, 특징 맵 채널이 여러개 있는데, 그걸 평균 때려서 어떤 값을 중요하게 생각하는지 보는 것인가보다)



근데 생각해보면 마지막 w같은 경우에는 추가학습이 필요할 것이다. 또한 GAP를 이미 사용하는 구조여야 할 것이다.
ResNet의 경우 이미 사용하고 있어서 적용이 가능하다고 한다.
Grad-CAM의 경우에는 w를 학습 없이 구할 수 있다고 한다. 그냥 수식 연산을 때리는거 같다. 아니 이런건 어떻게 찾는건지 모르겠다.
나는 엔지니어 할거니까 있는거 잘 쓰도록 하자... 이 경우 모델을 바꾸지 않고도 사용할 수 있다고 한다.

ViT 시각화
ViT의 핵심은 셀프 어텐션(Self-Attention) 메커니즘입니다. 셀프 어텐션은 입력의 모든 요소들이 서로를 어떻게 주목하는지를 학습하며, 각 요소의 중요도를 결정합니다. 이미지의 경우, 각 패치가 서로를 어떻게 "주목"하는지를 계산합니다.
ViT 시각화는 이러한 셀프 어텐션 메커니즘을 시각적으로 나타내는 방법입니다. 이를 통해 ViT가 예측을 수행할 때 이미지의 어떤 패치에 가장 주목하고 있는지를 알 수 있습니다.
ViT 시각화 방법
ViT 시각화는 주로 어텐션 맵(Attention Map)을 활용하여 모델이 입력 이미지의 특정 패치에 어떻게 주목하는지를 시각화합니다. ViT 시각화를 구현하는 방법에는 여러 가지가 있지만, 대표적인 방법은 다음과 같습니다:
- 어텐션 맵 추출: ViT의 Transformer 인코더에서 각 레이어의 셀프 어텐션 가중치(Q @ K)를 추출합니다. 일반적으로, 각 헤드(head)의 어텐션 맵은 입력 토큰 간의 유사성 또는 주목도를 나타내며, 이 정보를 통해 모델이 어떤 패치에 주목하고 있는지 알 수 있습니다.
- 어텐션 맵 시각화: 추출된 어텐션 맵을 시각화합니다. 이때, 각 패치의 위치에 따라 색상을 입혀 모델이 주목하는 부분을 강조합니다. 예를 들어, 높은 어텐션 값을 가진 패치는 더 밝은 색으로 표시될 수 있습니다.
- 어텐션 맵의 평균 또는 가중 합: 여러 레이어와 어텐션 헤드가 있는 경우, 각 헤드와 레이어에서의 어텐션 맵을 평균 또는 가중 합하여 최종 시각화 맵을 생성합니다.
- 원본 이미지와의 오버레이: 최종 어텐션 맵을 원본 이미지 위에 오버레이하여 모델이 주목하는 이미지의 영역을 시각적으로 확인할 수 있습니다. 이 과정을 통해 특정 클래스에 대한 모델의 주목 패턴을 이해할 수 있습니다.

코드로 보면 이런 식으로 간단하다. 조금 까다로운건 stack., squeeze 연속으로 써서 차원이 좀 헷갈린다.
stack을 한 것은 헤드가 여러개 나오기 때문에 한 것이다. 이것을 squeeze 해서 1차원을 다시 펴주고 마지막 레이어만 추출해주나보다.
# ViT 모델 로드
model = ViTModel.from_pretrained('google/vit-base-patch16-224')
# 모델에 이미지 전달
outputs = model(**inputs)
attention = outputs.attentions
# 마지막 레이어의 어텐션 맵 가져오기
attention = torch.stack(attention).squeeze(1).detach().cpu().numpy()
attention = attention[-1] # 마지막 레이어의 어텐션 맵
# 어텐션 맵 시각화
fig, ax = plt.subplots(1, attention.shape[0], figsize=(20, 10))
데이터 증강
학습데이터의 분포가 실제 데이터의 분포를 모두 담을 수 없기 때문에 최대한 비슷하게 맞추어 주려는 노력이다.
데이터의 밝기를 조절하거나, 돌리거나, 일부를 자르거나 한다.
요즘은 pytorch에서 이런 기능을 제공해주어 편하게 사용할 수 있다.

PyTorch에서는 torchvision.transforms 모듈을 사용하여 데이터 증강(augmentation)을 간단하게 구현할 수 있습니다. 데이터 증강은 주어진 학습 데이터의 다양한 변형을 생성하여 모델의 일반화 성능을 향상시키는 기법입니다. 이를 통해 모델이 데이터의 다양한 변형에 대해 더 잘 일반화할 수 있도록 돕습니다. 예를 들어, 데이터의 밝기를 조절하거나, 이미지를 회전시키거나, 일부를 자르는 등의 변형을 수행할 수 있습니다. 이러한 변형은 훈련 데이터 세트를 확장하고 모델이 더 견고하게 학습되도록 돕습니다.
요런 식으로 사용한다.
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 데이터 증강을 위한 변환 설정
transform = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5), # 50% 확률로 이미지를 좌우 반전
transforms.RandomRotation(degrees=15), # -15도에서 15도 사이로 랜덤 회전
transforms.ColorJitter(brightness=0.2, # 밝기, 대비, 채도, 색조 변경
contrast=0.2,
saturation=0.2,
hue=0.1),
transforms.RandomResizedCrop(size=(224, 224), # 랜덤 크롭 후 크기 조정
scale=(0.8, 1.0)),
transforms.ToTensor() # 이미지를 텐서로 변환
])
# CIFAR-10 데이터셋 로드 (train 데이터셋에 대해 증강 적용)
train_dataset = datasets.CIFAR10(root='./data',
train=True,
transform=transform, # 위에서 정의한 데이터 증강 변환 적용
download=True)
그외에, affine-transformation, CutMix (이건 좀 유용하고 재밌을 것 같다.)

또, RandAugment을 많이 사용한다고 한다. (멘토님도 이게 생각보다 엄청 중요하다고 하심.)
RandAugment는 데이터 증강(data augmentation) 기법 중 하나로, 이미지 데이터 증강을 자동화하고 최적화하는 방법입니다. 이는 기존의 AutoAugment 기법의 단순화된 버전으로, 데이터 증강을 위한 정책(policy)을 랜덤으로 생성하여 적용합니다. RandAugment는 이미지 분류, 객체 탐지, 세그멘테이션 등 다양한 컴퓨터 비전 작업에서 데이터 증강을 통해 모델의 일반화 성능을 향상시킬 수 있습니다.
사용법은 간단하다.
# RandAugment 변환 설정
transform = transforms.Compose([
transforms.RandAugment(num_ops=2, magnitude=9), # RandAugment 적용
transforms.ToTensor() # 이미지를 텐서로 변환
])
'AI&ML > BoostCamp AI Tech' 카테고리의 다른 글
| [BoostCamp AI Tech] CLIP 개념부터 코드까지 살펴보기 (0) | 2024.09.05 |
|---|---|
| [끄적끄적] CNN의 역전파 (2) | 2024.09.01 |
| [BoostCamp AI Tech] Computer Vison Overview (4) | 2024.08.27 |
| [BoostCamp AI Tech] 데이터 시각화 (0) | 2024.08.22 |
| [BoostCamp AI Tech] 이미지 데이터 전처리 (0) | 2024.08.22 |



