
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 파이싼
- 백준
- 개발환경
- 손실함수
- 신경망 학습
- video retireval
- 티스토리챌린지
- streamlit
- 그리디 알고리즘
- 기계학습
- 경사하강법
- 오블완
- end to end
- 밑바닥부터 시작하는 딥러닝
- REST API
- BOJ
- 4948
- 15649
- 1101
- n과 m
- N-Queen
- 1002
- 재귀
- Python
- 9020
- 백트래킹
- pyenv
- Retrieval
- 가상환경
- 파이썬
- Today
- Total
파이톨치
[BoostCamp AI Tech] U-Net 본문
U-Net

생긴 것부터 U자 모양으로 생긴 모델이다. 이름은 u-net이라고 하며 데이터를 축소시켰다가 up-sampling하면서 키운다.
의료 분야에서 효과적이라고 알려져있을뿐만 아니라, 일반적인 segmentation에서도 효과적이라고 한다.
인코더의 층을 디코더의 층에 concatenate 해주게 된다. 일종의 skip-connection이다.
resolution 크기가 안 맞는 경우에는 crop을 해서 맞추어준다.
단순화된 구조를 보면 다음과 같다.

중간에 있는 Conv 블록은 다음과 같이 구성된다.
def CBR2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias = True):
return nn.Sequential(
nn.Conv2d(in_channels = in_channels,
...
),
# 구조에 따라 쓰기도 하고 안 쓰기도 한다.
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU()
)이 블록을 토대로 encoder를 쌓는다. 그리고 MaxPool2d 층을 지나게 되면서 해상도가 낮아지게 된다.
이때 커널 사이즈는 2로 하여 1/2로 줄이게 된다. 그렇게 receptive field 크기를 키워가게 되는 것이다.
이것을 이용해서 또 다시 하나의 블록을 만들게 된다.
self.env1_1 = CBR2D(1, 64, 3, 1, 0)
self.env1_2 = CBR2D((64, 64, 3, 1, 0)
self.pool1 = nn.MaxPool2d(kernel_size=2)
이것을 다시 Transpose를 사용해서 크게 키워주는거다.
올릴 떄, 채널 수도 올리고, 해상도도 높여주는거다
self.upconv4 = nn.ConvTranspose2d(1024, 512,
kernel_size=2, stride=2, padding=0, True)
이제 이것을 다시 합쳐줘야 한다. residual 느낌으로 해줘야 한다.
근데 넣을 떄 사이즈가 맞지 않기 때문에 crop을 해주고 합쳐준다.
crop_env4_2 = crop_img(enc4_2, upconv4.size()[2])
cat4 = torch.cat(upconv4, crop_enc4_2, dim=1)
u-net 은 기본적으로 깊이가 4로 고정된다. 그렇기에 최고 성능을 보장하지 못하고 최적 깊이 비용이 높아진다.
이러한 한계를 극복하기 위해서 u-net ++ 에서는 dense skip connection을 가지게 된다.
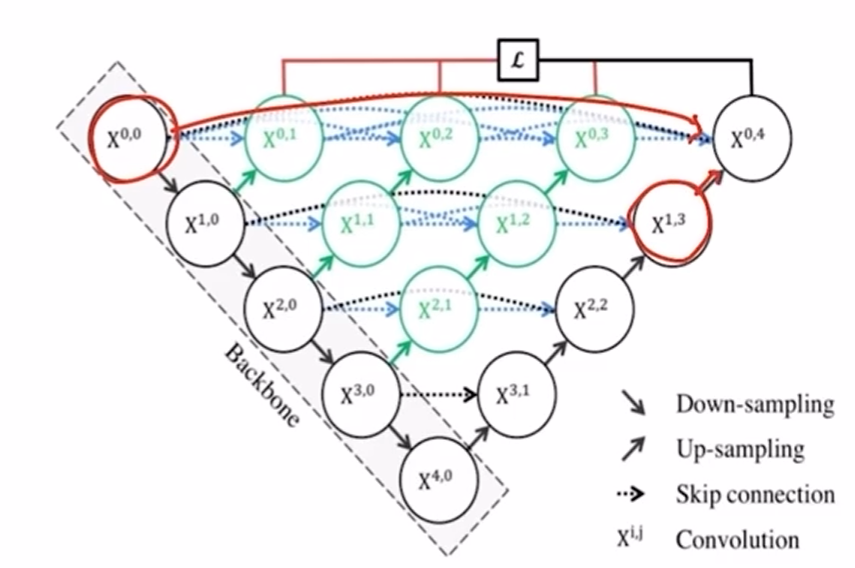
이렇게 하면 다양한 정보를 받을 수 있다.
아래에서 오는 정보도 받고 층별로 다른 모델도 가질 수 있게 되는 것이다.
또한 층별로 앙상블하는 효과도 있다.
대신에 이렇게 하면 파라미터 수가 늘어나게 된다. 또한 많은 connection으로 메모리도 많이 사용하게 된다.
# unet +++
u-net 디코더에서 같은 레벨의 인코더 층으로부터 feature map을 받는 simple skip connection 사용한다.
하지만 파라미터 수나 메모리가 늘어난다. full-scale에서 충분한 정보를 탐색하지 못해서 위차와 경계를 명시적을 학습하지 못한다.
좀 더 효율적인 형태의 모습을 보인다. 중간에 쓸데없는 층들이 사라지고 skip-connection을 하게 된다.
encoder-layer로부터 same-scale의 feature-maps를 받는다. (unet에서 했던 느낌 그대로 받는다.)
encoder-layer로부터 smaller-scale의 low-level feature maps를 받는다.
-> 풍부한 공간 정보를 통해 경계를 강조한다.
decoder layer로부터 larger-sclae의 high-level feature maps 받는다.
-> 어디에 위치하는지 위치 정보를 구현한다.
? 궁금한게 위로 올리거나 할 떄 해상도가 안맞는데 어떻게 넘기는거야:???
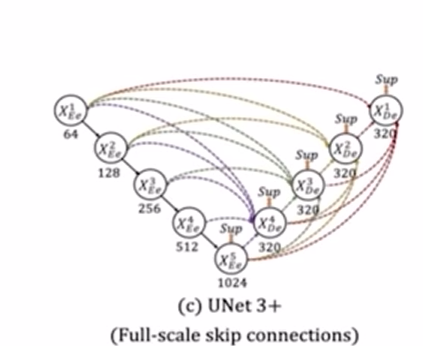

이렇게 함으로써 파라미터 수를 줄이면서 정확도를 높일 수 있었다. #
### classification guided Module
low-level 층에 남아 있는 background의 노이즈가 발생해서 많은 false-positive 문제가 발생하게 된다.
(! 낮은 층에서는 배경 정보가 남아 있는게 문제구나!)
'AI&ML > BoostCamp AI Tech' 카테고리의 다른 글
| [BoostCamp AI Tech] Segmentation 오답노트 (0) | 2024.11.21 |
|---|---|
| [BoostCamp AI Tech] 학습 시 고려 사항 (0) | 2024.11.20 |
| [BoostCamp AI Tech] Semantic Segmentation (0) | 2024.11.17 |
| [BoostCamp AI Tech] DilatedNet (0) | 2024.11.15 |
| [BoostCamp AI Tech] Hand Bone Image EDA (0) | 2024.11.13 |


