

250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- N-Queen
- 1002
- end to end
- 파이싼
- video retireval
- 15649
- 4948
- Retrieval
- REST API
- pyenv
- 개발환경
- 오블완
- 기계학습
- 가상환경
- 9020
- 재귀
- 신경망 학습
- 티스토리챌린지
- n과 m
- 경사하강법
- BOJ
- 백트래킹
- 1101
- 밑바닥부터 시작하는 딥러닝
- 파이썬
- Python
- 손실함수
- streamlit
- 그리디 알고리즘
- 백준
Archives
- Today
- Total
파이톨치
[BoostCamp AI Tech] Segmentation 오답노트 본문
728x90
Segmentation 오답노트
Pixel-Wise Classification
이는 이미지를 픽셀 단위로 분류하는 작업이다. 한 픽셀이 어떤 클래스에 들어가는지 예측하는 것이다. 대표적으로 세그멘테이션이 이러한 Pixel-wise classification으로 볼 수 있다. 대표적으로 FCN 모델이나 U-NET 모델이 있다.
CNN 파라미터 계산 및 Stride의 영향
생각보다 계산을 하는 상황이 있을 수도 있고, 전문가라고 한다면 이 정도는 가볍게 계산할 수 있어야 한다. output의 size는 kernel_size, stride, padding으로 계산이 된다. kernel_size는 빼주고, padding은 2곱해서 더해준다. stride로 나누어 주고 1을 더해주면 된다.
Run-Length-Encoding (RLE)
이는 정보를 압축하는 기술이다.
- 데이터를 압축하는 방식으로, 연속적으로 반복되는 값을 저장합니다.
- 예: 데이터 AAABBBCC는 3A3B2C로 압축됩니다.
- 이미지 세그멘테이션에서 마스크를 저장하거나 평가 지표에 활용됩니다.
이미지 세그멘테이션에서는 x,y 정보에다가 얼마나 아래로 긴지 써주는 단순한 방식이다.
FCN의 특징
- Fully Convolutional Networks는 완전히 컨볼루션 레이어로 구성된 네트워크입니다.
- 특징:
- 입력 이미지 크기와 상관없이 작업 가능.
- 픽셀 단위 출력(세그멘테이션).
- 업샘플링을 위해 Transposed Convolution 사용.
Transposed Convolution
- 업샘플링(특성 맵 크기 증가)에 사용됩니다.
- 컨볼루션의 역연산처럼 동작하지만, 실제로는 입력에 패딩을 추가하고 필터를 적용합니다.
- 주로 세그멘테이션 네트워크에서 디코더에 활용됩니다.
Receptive Field
- 한 뉴런이 입력 이미지에서 바라보는 영역의 크기입니다.
- 작을 때: 지역적 세부 정보를 잘 캡처하지만, 전체 컨텍스트를 놓칠 수 있습니다.
- 클 때: 전역 정보를 잘 반영하지만, 세부 정보가 희석될 수 있습니다.
- 강점:
- 작은 Receptive Field: ResNet 초기 레이어.
- 큰 Receptive Field: FPN, DeepLab.
Contracting Path
- U-Net에서 사용되며, 입력 이미지를 축소(다운샘플링)하여 높은 수준의 특성을 추출합니다.
- 주로 컨볼루션 + Max Pooling으로 구성됩니다.
U-Net++
- U-Net의 확장 버전.
- 특징:
- 더 많은 스킵 커넥션을 추가해 정보 손실 감소.
- 깊은 수직 및 수평 연결 구조.

“3 x 3 convolution Network + BN + ReLU) X 2” 연산
- CNN 블록 구성:
- 3x3 컨볼루션 → 배치 정규화(BN) → ReLU 활성화.
- 위 작업을 두 번 반복.
- 이 구성은 특성 추출과 비선형성 강화를 위해 일반적으로 사용됩니다.
SnapMix
- 데이터 증강 기법으로, MixUp과 비슷하지만 세그멘테이션에서 활용됩니다.
- 두 샘플을 혼합하고, 혼합된 라벨 정보를 유지합니다.

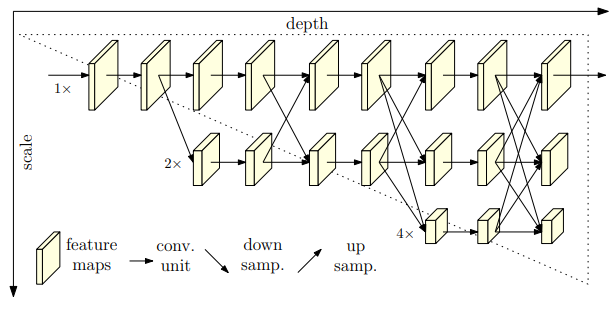
HRNet
- High-Resolution Network: 고해상도 정보를 유지하면서 학습하는 네트워크.
- 특징:
- 다중 해상도 스트림 유지.
- 고해상도 정보를 다른 스트림과 병합해 출력 향상.
Self-Attention Layer 계산 복잡도
- 계산 복잡도: O(N2×d)
- : 입력 토큰 수.
- : 각 토큰의 차원.
- 입력 길이가 길어질수록 복잡도가 기하급수적으로 증가합니다.
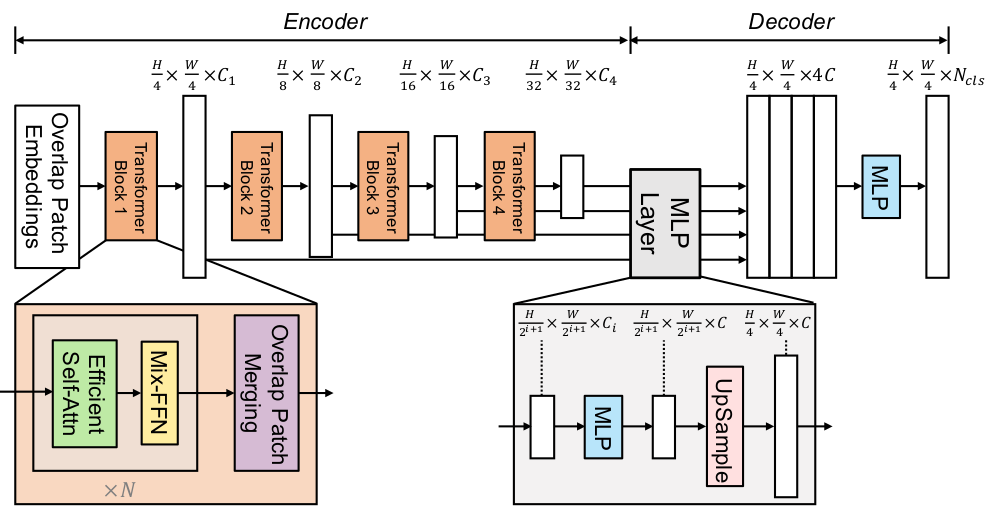
Segformer 아키텍처
- Segmentation Transformer로, 트랜스포머 기반 세그멘테이션 네트워크.
- 특징:
- 트랜스포머의 전역 정보와 CNN의 지역 정보를 결합.
- 효율적인 MLP 디코더 사용.
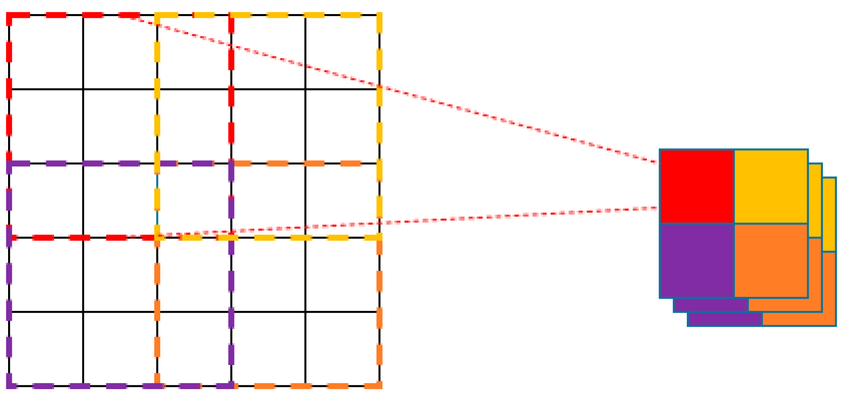
Overlapping Patch Merging
- 패치를 병합할 때 일부 패치가 겹치도록 처리.
- 정보를 보존하며, 더 세밀한 결과를 얻을 수 있습니다.
Local Continuity
- 지역적인 연속성을 강조하는 특성.
- 이미지 처리나 세그멘테이션에서 중요한 개념으로, 근접 픽셀 간의 상관관계를 반영합니다.
MLP Layer로 구성된 디코더 프로세스
- 트랜스포머 기반 네트워크에서, 디코더가 MLP 레이어로 전역 특성을 처리.
- Segformer에서는 입력 패치를 복원해 세그멘테이션 결과를 출력합니다.
WSSS (Weakly Supervised Semantic Segmentation)
- 약지도 방식 세그멘테이션: 완전한 픽셀 레벨 레이블 대신, 이미지 수준 라벨이나 제한된 정보로 학습.
- CAM (Class Activation Map)과 같은 기법 활용.
728x90
'AI&ML > BoostCamp AI Tech' 카테고리의 다른 글
| [Web] HTTP와 REST API (1) | 2024.12.11 |
|---|---|
| [BoostCamp AI Tech] 학습 시 고려 사항 (0) | 2024.11.20 |
| [BoostCamp AI Tech] U-Net (1) | 2024.11.18 |
| [BoostCamp AI Tech] Semantic Segmentation (0) | 2024.11.17 |
| [BoostCamp AI Tech] DilatedNet (0) | 2024.11.15 |
'AI&ML/BoostCamp AI Tech' Related Articles
more

