| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 1101
- 밑바닥부터 시작하는 딥러닝
- 4948
- Python
- pyenv
- streamlit
- 15649
- N-Queen
- 1002
- end to end
- n과 m
- 신경망 학습
- 그리디 알고리즘
- BOJ
- REST
- 오블완
- 티스토리챌린지
- 기계학습
- 경사하강법
- 백트래킹
- 파이썬
- 9020
- 파이싼
- 손실함수
- 개발환경
- 실버
- 백준
- REST API
- 가상환경
- 재귀
- Today
- Total
파이톨치
VideoLLaMA Series 본문
1. VideoLLaMA 2 Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
최근 인공지능(AI) 분야는 이미지 인식과 생성 기술의 획기적인 발전을 이루며, 의료 영상 분석과 자율 주행과 같은 다양한 산업에서 중요한 역할을 하고 있습니다. 특히 이미지 대형 언어 모델(Image-LLMs)은 정적 이미지 처리에서 강력한 성능을 보이며 인간 수준의 인식 능력에 도달하고 있습니다.
그러나 비디오 이해 및 생성(Video Understanding & Generation) 분야는 상대적으로 초기 단계에 머물러 있습니다. 비디오는 정적인 이미지와 달리 시간적 변화(Temporal Dynamics)와 동기화된 오디오 스트림(Synchronous Audio Streams)을 포함하고 있어, 더 풍부한 정보량을 제공하지만 동시에 처리의 복잡성을 증가시킵니다.
📌 Video-LLMs의 도전 과제
현재 비디오 대형 언어 모델(Video-LLMs)은 다음과 같은 한계점으로 인해 이미지 모델에 비해 발전 속도가 더딥니다.
1️⃣ 시간적 변화(Temporal Dynamics) 처리 부족
- 비디오 데이터를 효과적으로 분석하려면 시각적 패턴을 인식하는 동시에 시간에 따른 변화를 이해해야 함
- 현재 모델들은 다중 프레임 간 특징을 효과적으로 융합하지 못함 → 미래 상태 예측이 어려움
2️⃣ 오디오 정보의 활용 부족
- 오디오는 장면을 이해하는 데 중요한 맥락 정보를 제공하지만, 현재 모델들은 오디오 처리를 제대로 하지 못함
- 멀티모달(다중 데이터 유형) 분석의 한계를 초래, 모델의 종합적 이해 능력이 부족
🎯 VideoLLaMA 2의 등장
이러한 문제를 해결하기 위해, VideoLLaMA 2는 비디오-언어 이해(Video-Language Understanding)를 강화하는 비디오 LLM으로 개발되었습니다.
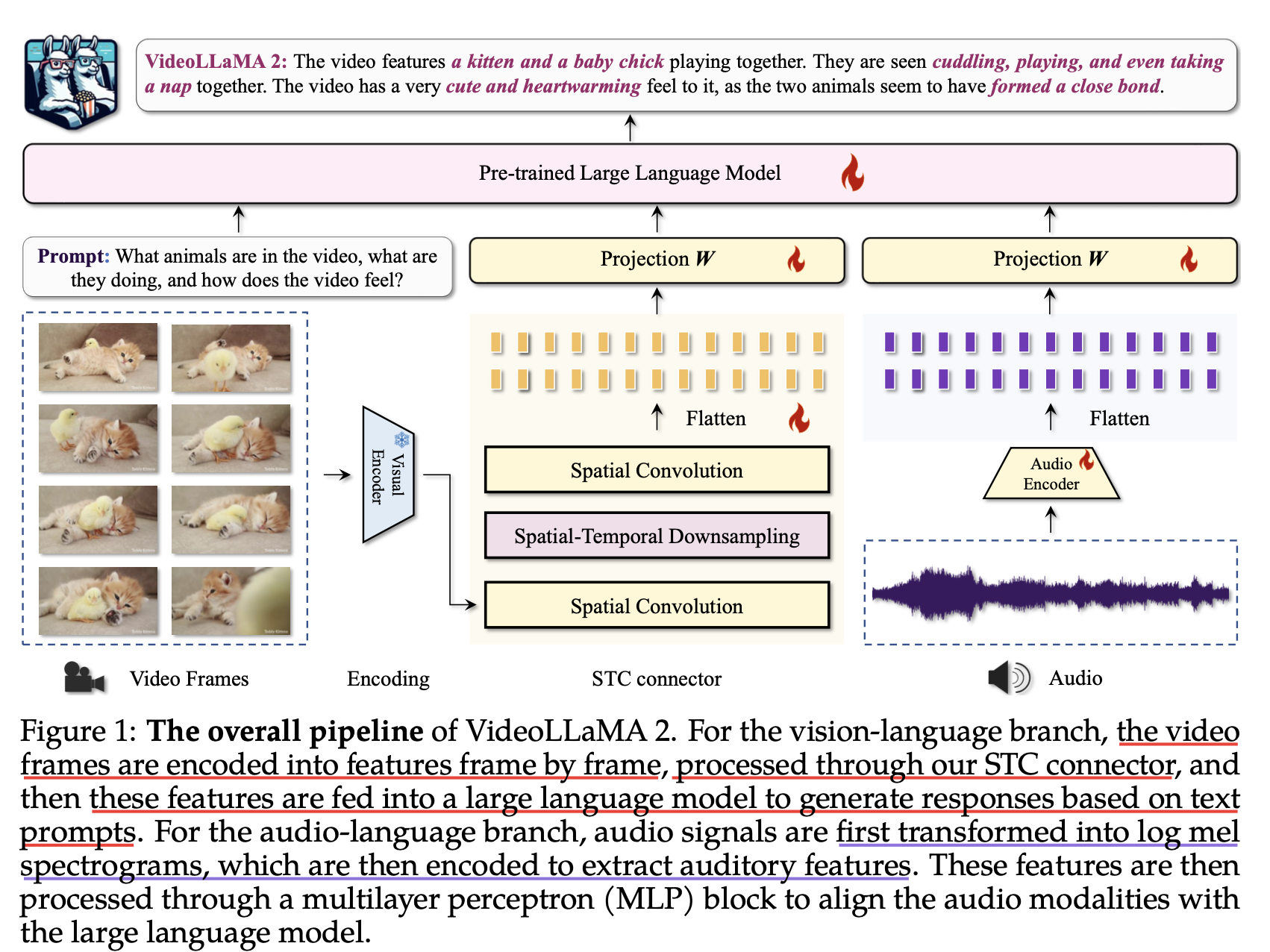
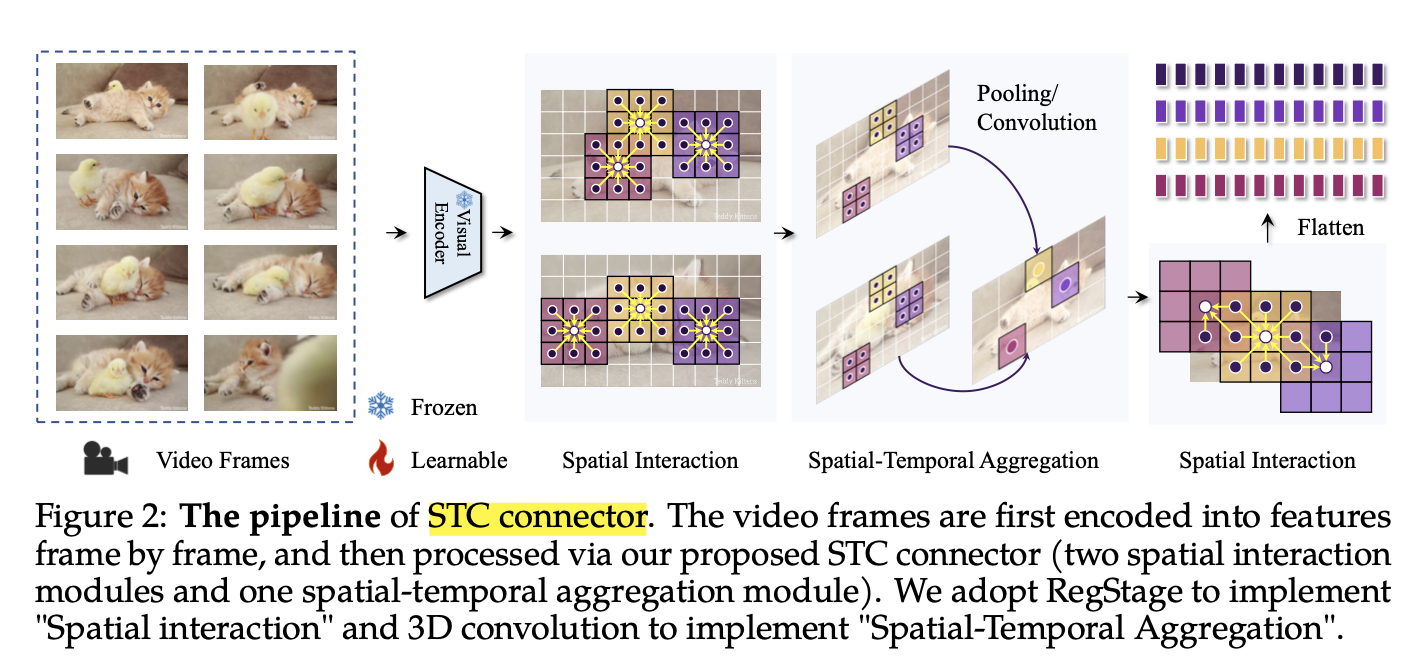
✔ 특수 설계된 공간-시간 연결 모듈(Spatial-Temporal Connector)을 통해 시간적 변화 처리 성능 개선





✔ 오디오 브랜치(Audio Branch)를 도입하여 멀티모달 통합 강화
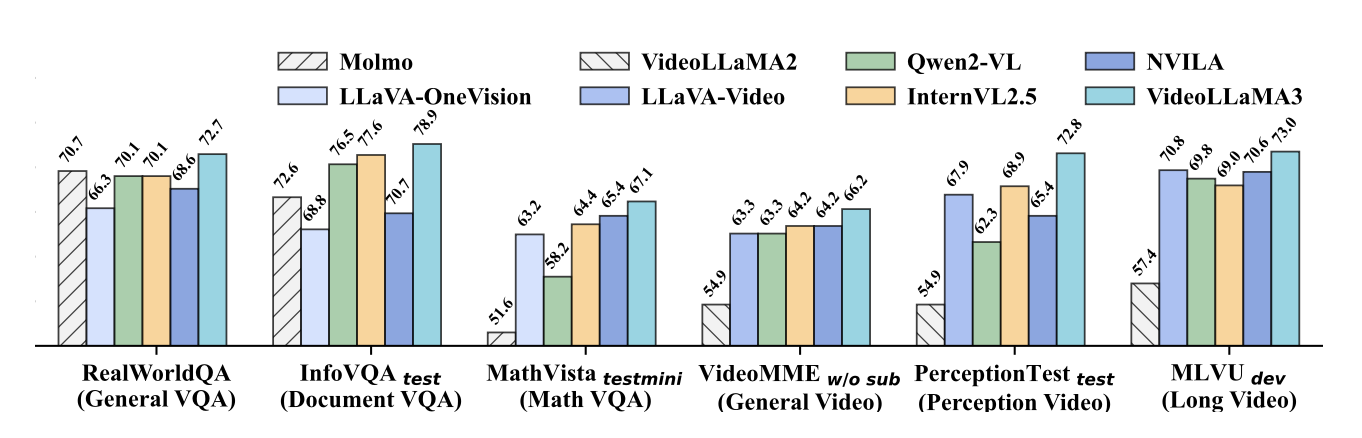
✔ 비디오 캡셔닝(Video Captioning) 및 질의응답(QA)과 같은 다양한 비디오-언어 과제에서 우수한 성능
2. VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding