
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 오블완
- 가상환경
- 파이싼
- 밑바닥부터 시작하는 딥러닝
- 1101
- 개발환경
- 경사하강법
- 기계학습
- 15649
- 티스토리챌린지
- n과 m
- REST API
- 파이썬
- 9020
- 그리디 알고리즘
- 손실함수
- N-Queen
- streamlit
- pyenv
- 백트래킹
- 신경망 학습
- BOJ
- 백준
- 4948
- Python
- REST
- 실버
- 재귀
- 1002
- end to end
- Today
- Total
파이톨치
Visual Shortcomings of Multimodal LLMs 본문
1. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
✅ 멀티모달 대형 언어 모델(MLLMs)의 발전과 한계
최근 MLLMs(Multimodal Large Language Models)는 빠르게 발전하며 이미지 이해, VQA(Visual Question Answering), 명령 수행 등에서 뛰어난 성능을 보이고 있다. 특히 GPT-4V(ision)의 등장은 MLLM의 성능을 새로운 수준으로 끌어올렸다.
하지만 MLLMs에는 여전히 시각적 한계가 존재하며, 일부는 매우 기초적인 문제이기도 하다. 이 문제의 원인은 시각적 표현 부족인가? 언어 이해의 한계인가? 아니면 둘 사이의 정렬(alignment) 문제인가? 이 연구는 MLLMs의 한계가 시각적 표현(visual representation ) 문제에서 비롯된 것일 가능성이 크다고 주장한다.
✅ CLIP-blind pairs: CLIP이 제대로 구별하지 못하는 이미지 쌍

- CLIP은 때때로 시각적으로 분명히 다른 두 이미지를 유사하게 인코딩하는 경우가 있다.
- 이러한 경우를 CLIP-blind pairs라고 정의.
- 이를 측정하기 위해 DINOv2(비전 전용 자기지도 학습 모델)의 임베딩을 비교하여 CLIP과 다르게 인코딩되는 이미지를 탐색.
이 CLIP-blind pairs는 MLLMs에도 직접적인 오류를 유발한다.
✅ MMVP 벤치마크 도입 및 실험 결과
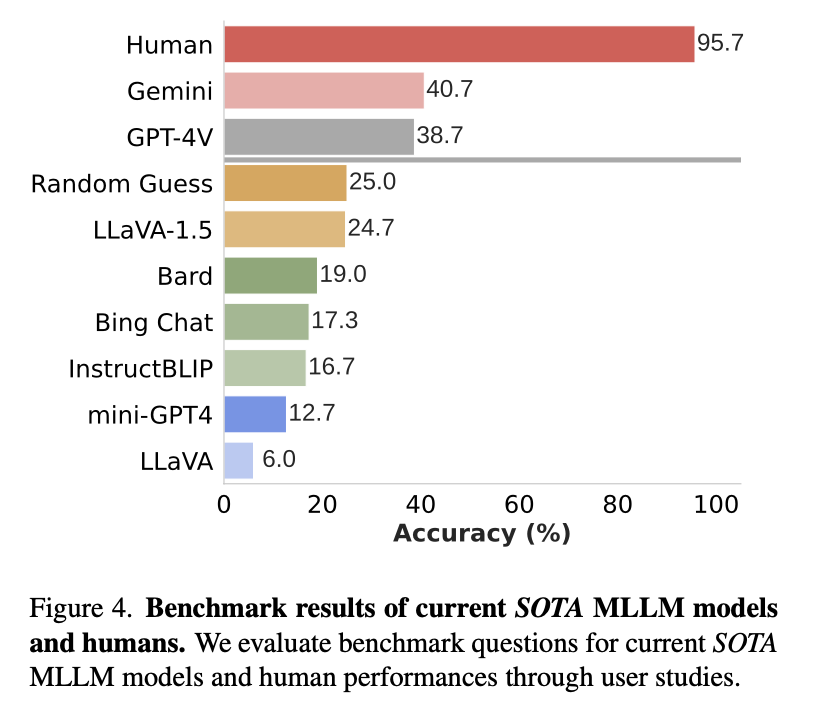
- MMVP(Multimodal Visual Patterns) 벤치마크를 구축하여 CLIP-blind pairs를 기반으로 MLLMs의 시각적 이해 능력을 평가.
- GPT-4V를 포함한 여러 오픈소스 및 폐쇄형 MLLMs(예: GPT-4V, 기타 비공개 모델 등)을 테스트.
- MLLMs는 간단한 시각적 질문에서도 낮은 성능을 보이며, 대부분 랜덤 추측보다도 못한 결과를 나타냄.
- GPT-4V는 예외적으로 더 나은 성능을 보였지만, 여전히 인간과 비교하면 50% 이상의 성능 차이를 보임.
✅ 해결책: Mixture-of-Features (MoF) 접근법

- CLIP 기반 MLLMs의 시각적 한계를 해결하기 위해 비전 전용 자기지도 학습 모델(예: DINOv2)을 결합하는 방법을 탐색.
- 두 가지 MoF 방법을 제안:
- A-MoF (Additive MoF): CLIP과 DINOv2 특징을 선형적으로 혼합
- DINOv2가 시각적 이해 능력을 크게 향상하지만, 명령 수행 능력이 감소하는 문제가 발생.
- I-MoF (Interleaved MoF): CLIP과 DINOv2의 시각 토큰을 공간적으로 혼합
- 시각적 이해를 향상시키면서도 명령 수행 능력을 유지하는 효과적 방법으로 확인.
- A-MoF (Additive MoF): CLIP과 DINOv2 특징을 선형적으로 혼합
✅ 결론 및 시사점
이 연구는 MLLMs가 여전히 시각적 표현 학습에 한계를 가지고 있으며, CLIP 기반 비전 인코더가 병목 역할을 할 가능성이 크다는 점을 밝혀냈다.
따라서, 단순한 데이터 증가나 모델 크기 확장이 아닌, 새로운 시각적 표현 학습 방식이 필요하며,
MoF 같은 접근법이 이러한 문제를 해결하는 데 기여할 수 있음을 보였다.
2. Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Cambrian-1은 비전 중심(multimodal LLM, MLLM) 접근 방식을 기반으로 설계된 모델. 기존 MLLM들은 강력한 언어 모델을 활용하지만, 비전 컴포넌트의 설계가 충분히 탐색되지 않거나 시각적 표현 학습과 단절되는 경우가 많다. 이로 인해 실제 환경에서의 감각적 정렬(sensory grounding) 이 어려워지는 문제가 발생.
🔎 연구 주요 내용
📌 비주얼 표현 평가
- LLM과 시각적 지시 튜닝(Visual Instruction Tuning) 을 통해 다양한 시각적 표현 학습 방식(자기 지도 학습, 강한 지도 학습, 조합형 모델 등) 을 비교
- 20개 이상의 비전 인코더(Vision Encoder) 실험을 통해 다양한 모델 및 아키텍처의 성능 분석


📌 기존 MLLM 벤치마크의 한계 분석
- 기존 멀티모달 벤치마크는 다양한 작업 결과를 통합하고 해석하는 데 어려움이 있음
- 이를 보완하기 위해 새로운 비전 중심 벤치마크 "CV-Bench" 제안
📌 시각적 정렬 향상을 위한 방법 제안
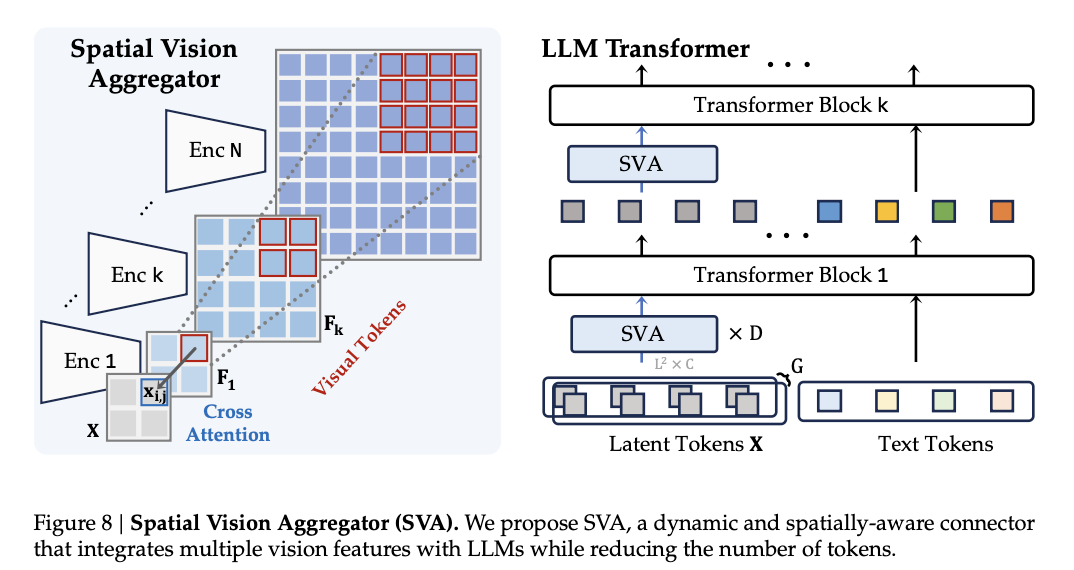
- Spatial Vision Aggregator (SVA):
- 고해상도 비전 특징(high-resolution vision features) 을 LLM과 효과적으로 통합
- 토큰 수를 줄이면서도 중요한 시각 정보 유지
📌 고품질 시각적 지시 튜닝 데이터 구축
- 공개 데이터 소스 활용 🗂️
- 데이터 출처의 균형 및 분포 조정의 중요성 강조
📌 결론
- Cambrian-1은 최첨단 성능(State-of-the-art)을 달성
- Instruction-Tuned MLLM을 위한 포괄적인 오픈소스 프레임워크
- 모델 가중치, 코드, 지원 도구, 데이터셋, 튜닝 및 평가 방법 공개
'논문' 카테고리의 다른 글
| INTERNVIDEO2: SCALING FOUNDATION MODELS FORMULTIMODAL VIDEO UNDERSTANDING (0) | 2025.04.07 |
|---|---|
| VideoLLaMA Series (0) | 2025.04.02 |
| InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation (0) | 2025.04.02 |
| Cambrian-1: A Fully Open, Vision-CentricExploration of Multimodal LLMs (0) | 2025.04.02 |
| [Paper review] LLaVA Series (2) | 2025.04.01 |



