
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- n과 m
- REST
- 기계학습
- 파이싼
- 오블완
- 4948
- pyenv
- REST API
- BOJ
- 15649
- 손실함수
- 백준
- Python
- 신경망 학습
- 1002
- 1101
- 밑바닥부터 시작하는 딥러닝
- 티스토리챌린지
- 재귀
- 경사하강법
- 실버
- 백트래킹
- 그리디 알고리즘
- 파이썬
- end to end
- 9020
- N-Queen
- 개발환경
- 가상환경
- streamlit
Archives
- Today
- Total
파이톨치
[Paper review] LLaVA Series 본문
728x90
1. LLaVA (Visual Instruction Tuning)
기계 생성된 명령 수행 데이터를 사용한 대형 언어 모델(LLM)의 명령 튜닝(instruction tuning)은 새로운 작업에 대한 제로샷(zero-shot) 성능을 향상시키는 것으로 알려져 있다.
하지만, 다중모달(multimodal) 분야에서는 아직 연구가 부족하다. 이에 우리는 GPT-4를 활용하여 다중모달(언어-이미지) 명령 수행 데이터를 생성하는 첫 번째 시도를 소개한다.

연구의 주요 기여
본 논문에서는 시각 명령 튜닝(Visual Instruction-Tuning)이라는 개념을 도입하여, 기존의 명령 튜닝을 언어-이미지 다중모달 영역으로 확장하는 첫 번째 시도를 제시한다. 주요 기여는 다음과 같다.

- 다중모달 명령 수행 데이터 구축
- 비전-언어 명령 수행 데이터 부족이라는 주요 문제를 해결하기 위해, ChatGPT/GPT-4를 활용하여 기존 이미지-텍스트 페어 데이터를 적절한 명령 수행 형식으로 변환하는 데이터 생성 파이프라인을 개발하였다.
- 대형 다중모달 모델 개발
- CLIP의 오픈셋(개방형) 시각 인코더와 Vicuna 언어 디코더를 연결하여 대형 다중모달 모델(LMM, Large Multimodal Model)을 구축하였다.
- 생성된 명령 수행 데이터를 이용해 모델을 엔드투엔드(end-to-end)로 미세 조정(fine-tuning)하였으며, 실험 결과 이를 통한 명령 튜닝이 효과적임을 검증하였다.
- GPT-4와 결합(ensemble)하여 Science QA 다중모달 추론 데이터셋에서 최첨단 성능(SoTA, State-of-the-Art)을 달성하였다.
- 다중모달 명령 수행 벤치마크(LLaVA-Bench) 구축
- 다양한 이미지-명령 페어와 상세한 주석(annotation)을 포함한 두 가지 어려운 벤치마크를 개발하여, 다중모달 명령 수행 모델의 평가를 위한 표준을 제공하였다.
2. LLaVA-1.5 (Improved Baselines with Visual Instruction Tuning)
LLM에서 instruction tuning을 하면 성능이 올라가는 것으로, 알려짐.
때문에 이를 LMM에도 적용시키려는 연구임.
주요 개선 사항
- MLP 기반 크로스모달 커넥터 적용
- VQA(Visual Question Answering) 등 학술적 과제 관련 데이터 추가
- 이 두 가지 개선은 LLaVA 프레임워크와 독립적(orthogonal)이지만 LLaVA와 결합하면 다중모달 이해 능력이 향상됨

- 고해상도 입력 처리
- 이미지를 격자로 나누는 방식으로 고해상도 입력을 효과적으로 처리 가능
- 모델의 세부 인식 능력을 향상시키고, 환각(hallucination) 현상을 감소시킴
- 구성적(compositional) 능력
- 장문의 언어 추론 학습과 짧은 시각적 추론 학습을 병행하면 멀티모달 질문에서의 글쓰기 능력이 향상됨
- 데이터 효율성
- 학습 데이터의 최대 75%를 무작위로 제거해도 성능 감소가 미미
- 보다 정교한 데이터 압축 전략을 활용하면 학습 효율성을 더욱 높일 가능성 존재
- 데이터 확장(data scaling)
- 데이터의 세밀한 구성과 모델의 성능 확장이 중요한 역할을 함
- 불필요한 인공적인 오류(artifacts) 없이 모델 능력을 개선할 방법을 제시

배경
- Sec. 3.3에서 입력 이미지 해상도를 높이면 모델 성능이 향상됨을 확인함.
- 하지만, 기존 오픈소스 CLIP 비전 인코더는 최대 336×336 해상도 제한이 있어 단순히 비전 인코더를 교체하는 것만으로는 해결 불가능.
기존 방법의 한계
- ViT 기반 비전 인코더의 해상도를 확장하는 기존 접근법:
- 위치 임베딩 보간 (positional embedding interpolation)
- ViT 백본을 새로운 해상도에 맞춰 미세 조정 (fine-tuning)
- 문제점:
- 대규모 이미지-텍스트 페어 데이터셋이 필요
- 고정된 해상도만 지원 가능 (추론 시 유연한 해상도 조정 불가능)
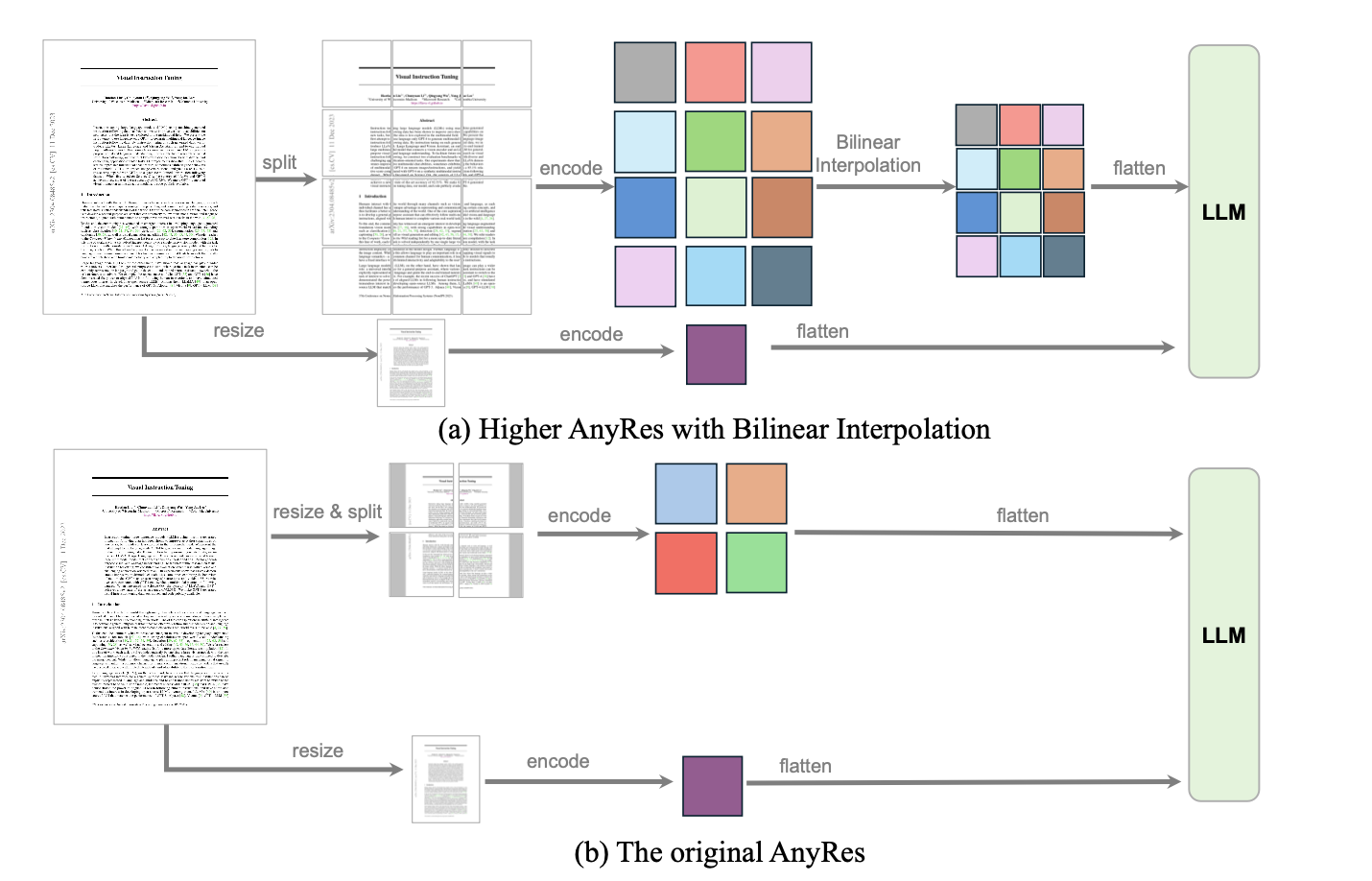
새로운 해결책: 이미지 패치 분할 방식
- 이미지를 작은 패치로 분할하여 기존 비전 인코더가 처리할 수 있는 해상도로 인코딩
- 각 패치의 특징 맵(feature map)을 개별적으로 추출한 후 결합하여 목표 해상도의 단일 특징 맵을 생성
- 이를 LLM에 입력하여 모델이 전체 이미지를 이해할 수 있도록 함
- 단순히 패치를 결합하면 정보 손실 발생 가능 => 이를 보완하기 위해 다운샘플링된 전체 이미지의 특징을 추가적으로 결합하여 전역적인 맥락 유지
3. LLaVA-OneVision (Easy Visual Task Transfer)
핵심 성과

- LLaVA-OneVision은 단일 모델로서 다양한 컴퓨터 비전 시나리오에서 오픈 LMM의 성능 한계를 확장하는 최초의 모델
- 단일 이미지 이해 (Single-image)
- 다중 이미지 이해 (Multi-image)
- 비디오 이해 (Video scenarios)
주요 특징
- 다양한 모달리티 및 시나리오 간 강력한 전이 학습 (Transfer Learning) 지원
- 이미지에서 비디오로의 학습 전이를 통해 강력한 비디오 이해 및 크로스 시나리오 능력 발휘
- 새로운 능력이 모델 내부에서 자연스럽게 등장 (Emerging Capabilities)


1. 단일 이미지 (Single-image)
- 원본 해상도를 유지하기 위해 최대 공간 구성 (a, b) 사용
- 한 이미지당 많은 시각적 토큰을 할당하여 긴 시퀀스로 시각적 신호를 효과적으로 표현
- 이미지는 비디오보다 고품질 학습 샘플과 다양한 지침이 많음
- 이미지 표현을 비디오 표현 방식과 유사하게 설계하여 이미지에서 비디오로의 전이 학습을 용이하게 함
2. 다중 이미지 (Multi-image)
- 기본 해상도(384x384)만 사용하여 비전 인코더에 입력 → 특징 맵(feature map) 생성
- 고해상도 이미지를 여러 번 자르는 방식(multi-crop) 불필요 → 계산 비용 절감
3. 비디오 (Video)
- 각 프레임을 기본 이미지 해상도로 리사이징 후 비전 인코더를 통해 특징 맵 생성
- Bilinear interpolation(쌍선형 보간)을 사용하여 토큰 수를 줄이고 더 많은 프레임을 고려
- 성능과 계산 비용 간 최적의 균형을 제공
4. LLaVA-Video (VIDEO INSTRUCTION TUNING WITH SYNTHETIC DATA)
멀티모달 학습에서 대규모 연산과 데이터가 핵심 요소가 되는 시대에, Visual Instruction Tuning 기법이 일반적인 비주얼 어시스턴트 구축의 기초를 마련함. 그러나 고품질 비디오-언어 데이터 수집의 어려움으로 인해 기존 비디오 멀티모달 모델의 발전이 제한됨.
기존 비디오-언어 데이터셋의 문제점
- 고품질 비디오 확보의 어려움
- 기존 데이터셋의 비디오는 상대적으로 정적인(static) 장면이 많음
- 씬 변경을 기준으로 잘려 있어 스토리 흐름이 단순화됨
- 희소한 프레임 샘플링 문제
- 예: ShareGPT4Video는 30초짜리 비디오에서 평균 2프레임만 샘플링
- 이는 전체적인 장면 설명에는 유용하나, 세부 동작을 포착하지 못함
- 세부적인 설명이 필요한 경우 환각(hallucination) 발생 가능
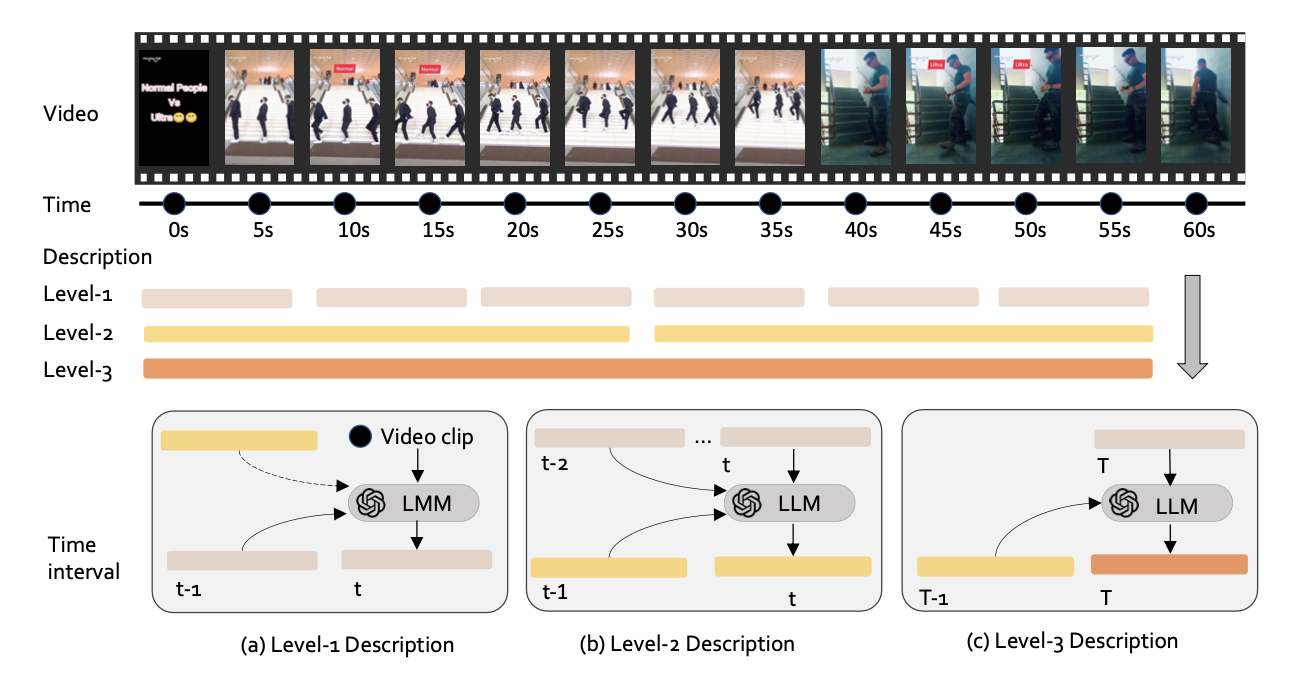
고품질 합성 데이터셋 생성
- LLaVA-Video-178K: 비디오 명령(instruction-following) 수행을 위한 고품질 합성 데이터셋
- 반복적(Recurrent) 캡션 생성 시스템 도입
- 10초 단위 → 전체 영상 길이까지 3단계의 캡션 생성
- 이전 캡션을 맥락으로 활용하여 점진적으로 상세한 캡션 추가
- 프레임 샘플링 전략 개선
- 초당 1프레임(1fps) 밀집 샘플링 적용 → 기존보다 상세한 특징 반영 가능
- 다양한 질문-응답 생성
- 기존 비디오 QA 데이터셋 분석을 기반으로 16가지 질문 유형 정의
- GPT-4o를 활용해 개방형 질문 + 객관식 질문 생성

728x90
'논문' 카테고리의 다른 글
| INTERNVIDEO2: SCALING FOUNDATION MODELS FORMULTIMODAL VIDEO UNDERSTANDING (0) | 2025.04.07 |
|---|---|
| VideoLLaMA Series (0) | 2025.04.02 |
| InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation (0) | 2025.04.02 |
| Visual Shortcomings of Multimodal LLMs (0) | 2025.04.02 |
| Cambrian-1: A Fully Open, Vision-CentricExploration of Multimodal LLMs (0) | 2025.04.02 |
'논문' Related Articles
more



